Структура переноса (Transfer Structure) в PaPM – это функция обогащения данных, которая может использоваться для переноса данных в соответствии с предопределенными полями условий и настройками. Если эти условия не выполняются, функция Структуры переноса сохраняет исходные данные.
Структура переноса (Transfer Structure) в PaPM: Заголовок функции
Многие поля заголовка аналогичны по смыслу полям функции Распределение (Allocation), которая рассматривалась тут и в принципе относятся к Функциональным строительным блокам и не являются специфичными для определенной функции.
Тип структуры переноса (Transfer Structure Type)

Используются две настройки, которые по сути являются транспонированием:
Стандартная структура переноса
![]()
Перенос значений из строк в столбцы.
Обратная структура переноса
Обратное действие, перенос из столбцов в строки.
Использовать исходные данные (Include original Input Data)
Значение: Да/Нет.
Если выбрать Да, система добавит исходные входные данные (записи) к выходным данным (записям) вместе с полученными результатами или при отсутствии результатов.

Поле Использовать исходные данные = Да. В данном случае в поле Обработка результата = Включить обогащённые данные (см. ниже) и была ошибка обогащения данных (правило не выполнено), но исходные данные отражены в результатах функции.
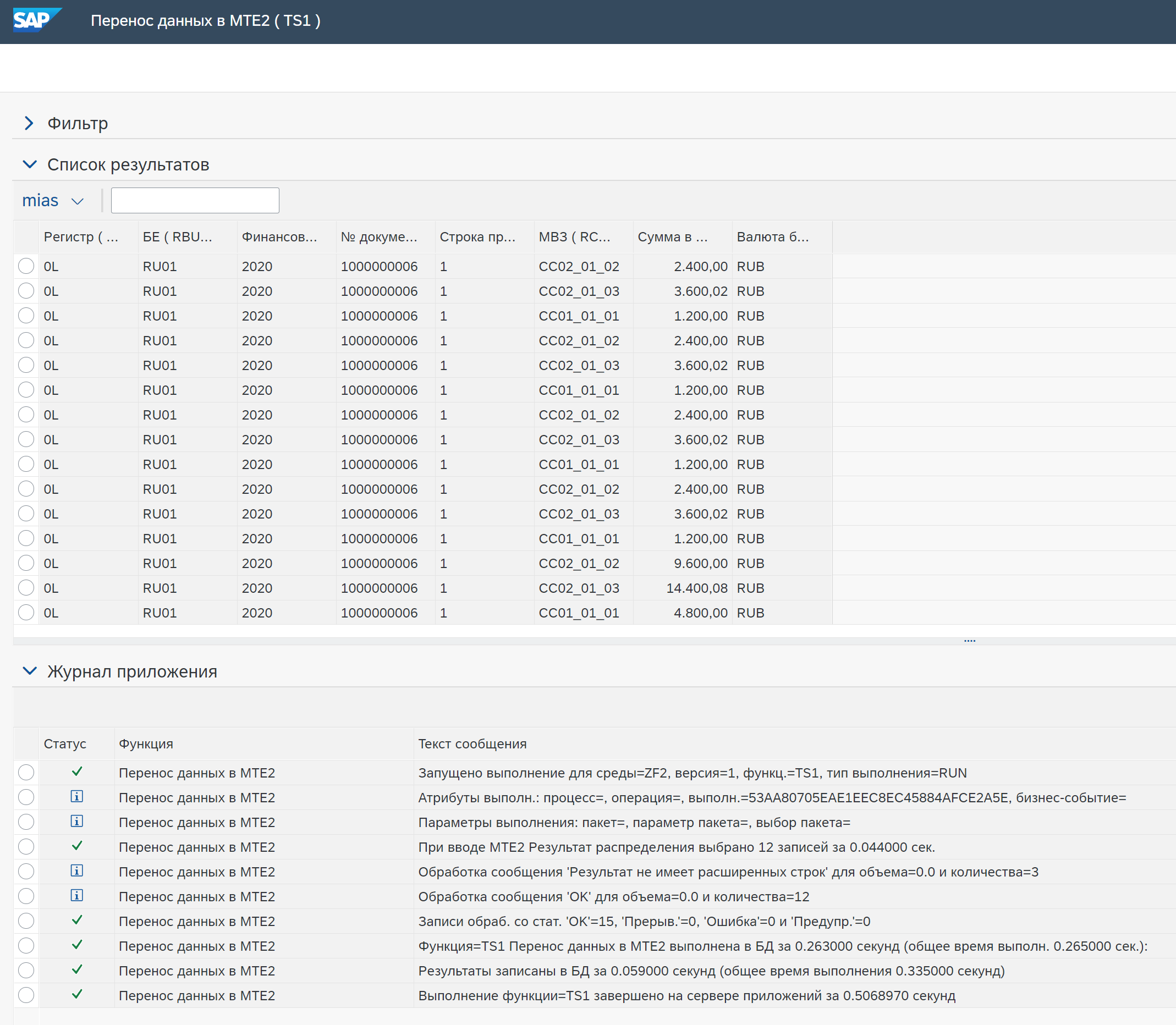
Поле Использовать исходные данные = Да. В данном случае поле Обработка результата = Включить все данные (см. ниже), но правило не выполнено. В результате отражены исходные данные и в последних трех строках результат применения агрегации к исходным данным согласно настроек функции (поле Результат агрегации = Группирование по признакам).
Вывод исходных данных облегчает моделирование требований в тех случаях, когда один сценарий строится поверх другого. В этом случае необходимо сохранить исходные результаты сценария и добавить к ним дополнительные результаты.
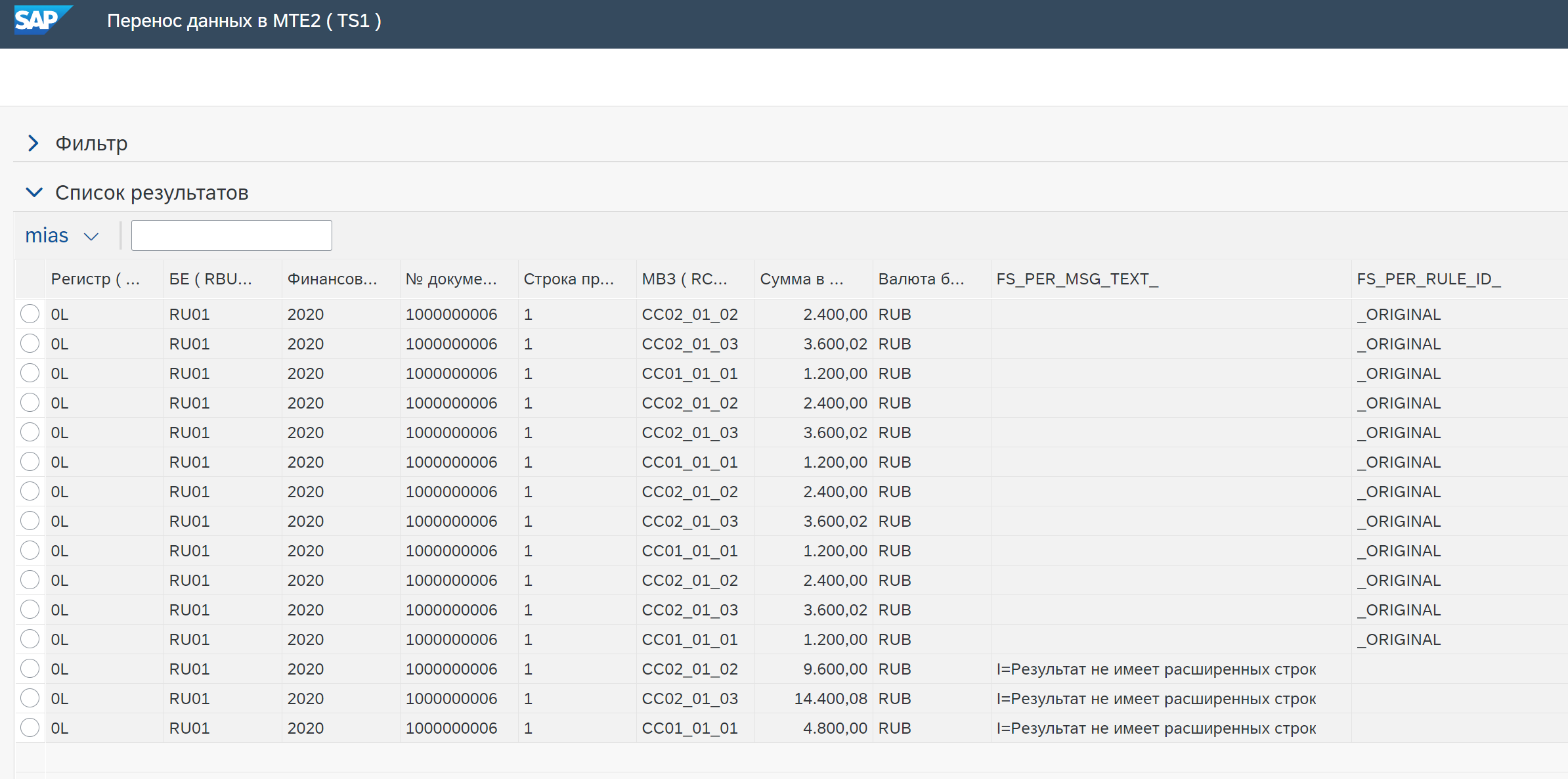
В результатах выполнения функции можно вывести поля, идентифицирующие исходные данные, и результат работы функции.
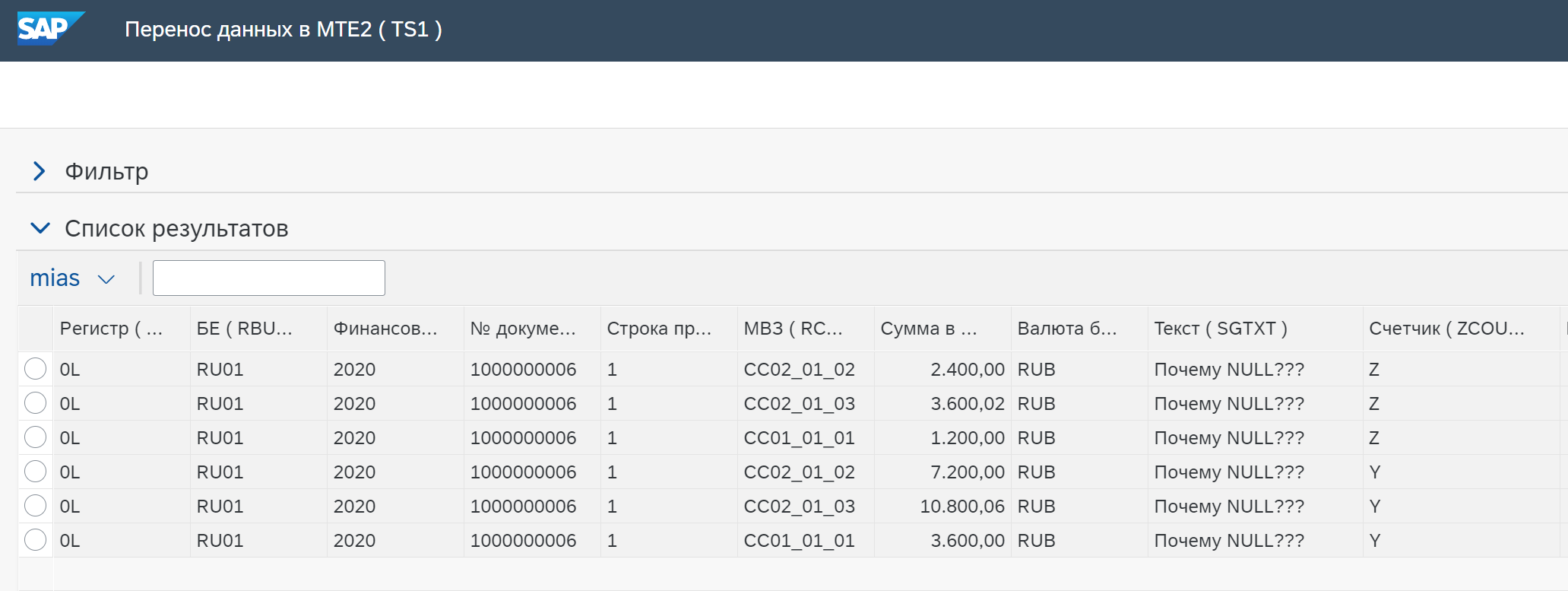
Нужно учитывать следующий момент: если используются исходные данные (значение в поле Использовать исходные данные = Да), и при этом в исходных данных есть поля с NULL (не с пустыми значениями, а именно с NULL)
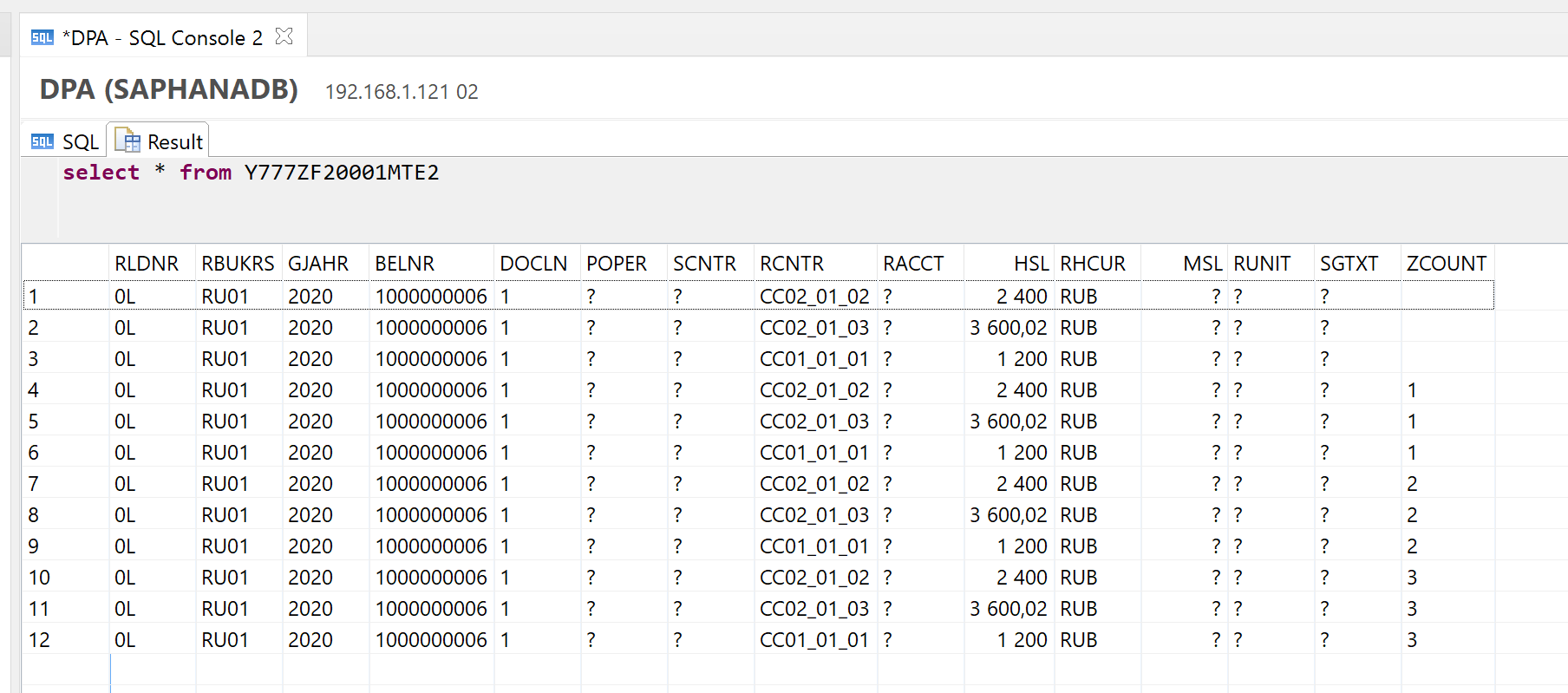
(тут ? обозначает NULL)
то будет ошибка:
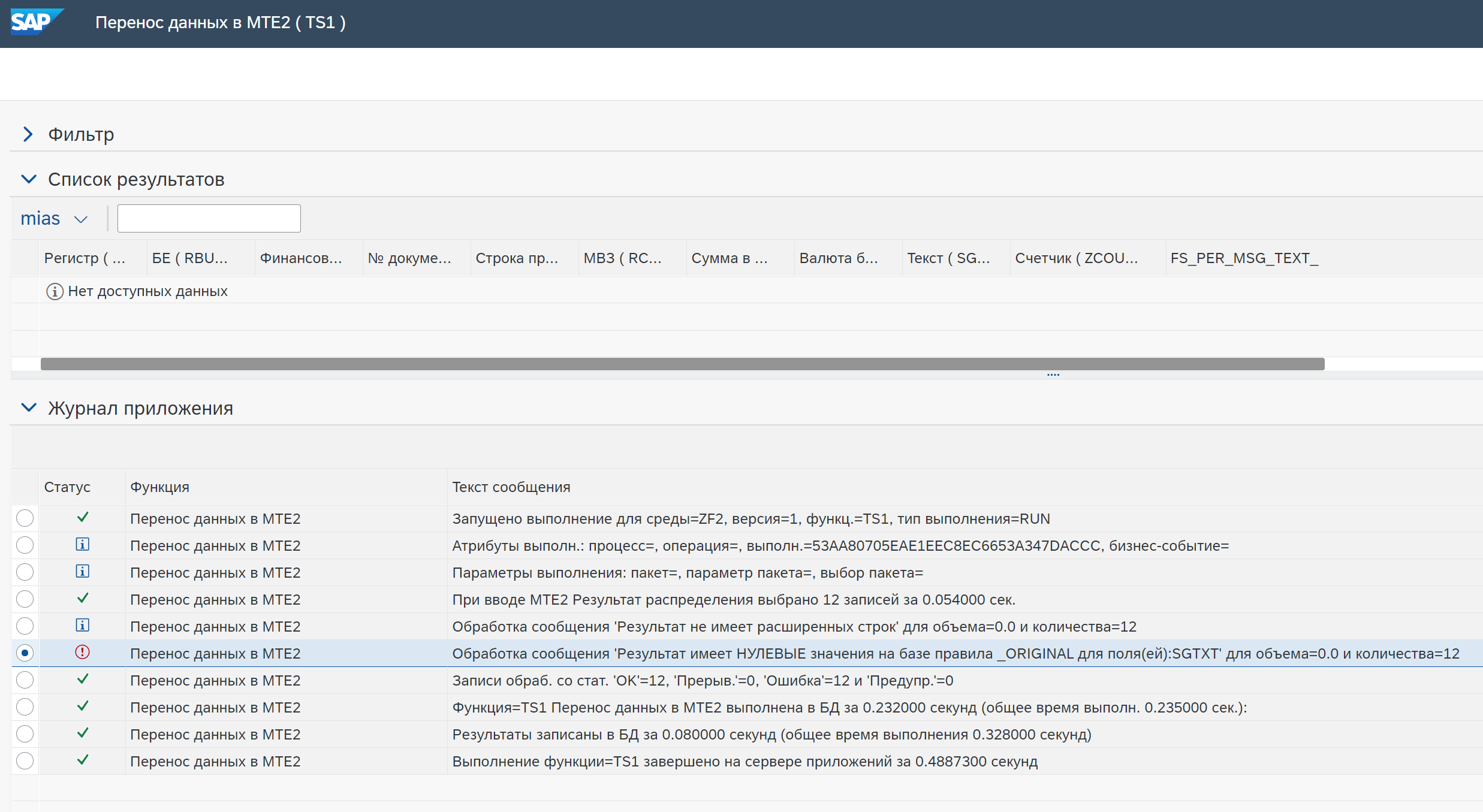
Для исключения ошибки, данные поля (с NULL) необходимо исключить из вывода, то есть в поле Сохранить поля выбрать Все поля кроме полей ‘Выбор операции &’->’Источник’ (All Fields except Selection & Action->Source Fields) и на вкладке Ключи (Signature) в разделе Выбор (Selection) указать поля для исключения.
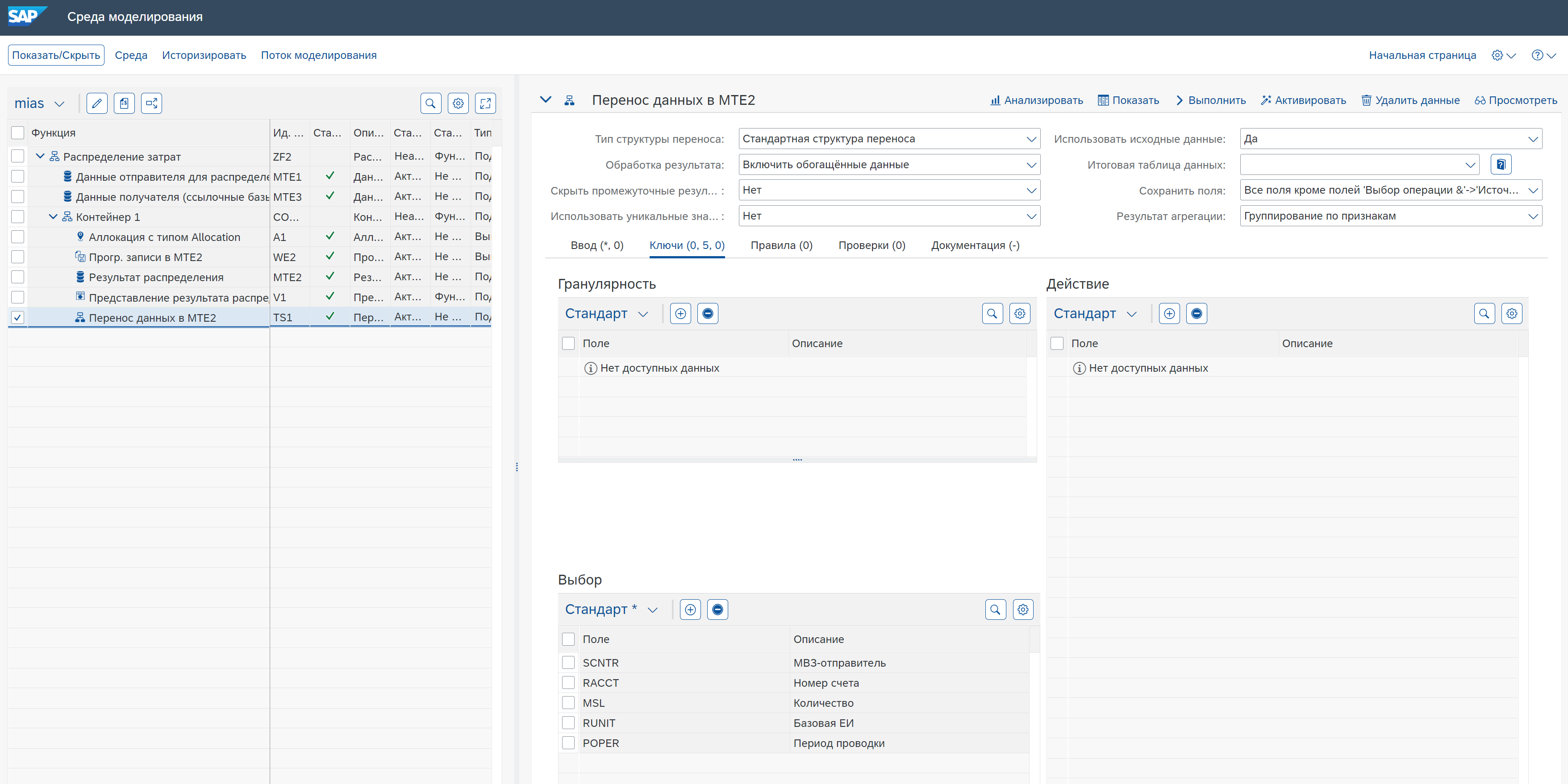
Либо обеспечить заполнение полей значениями, пусть даже и пустыми на предыдущих этапах обработки данных.
Также такие поля можно обработать на вкладке Ввод. Например, указав для нужного поля формулу, с использованием функции обработки NULL: IFNULL (SGTXT, ‘Почему NULL???’)
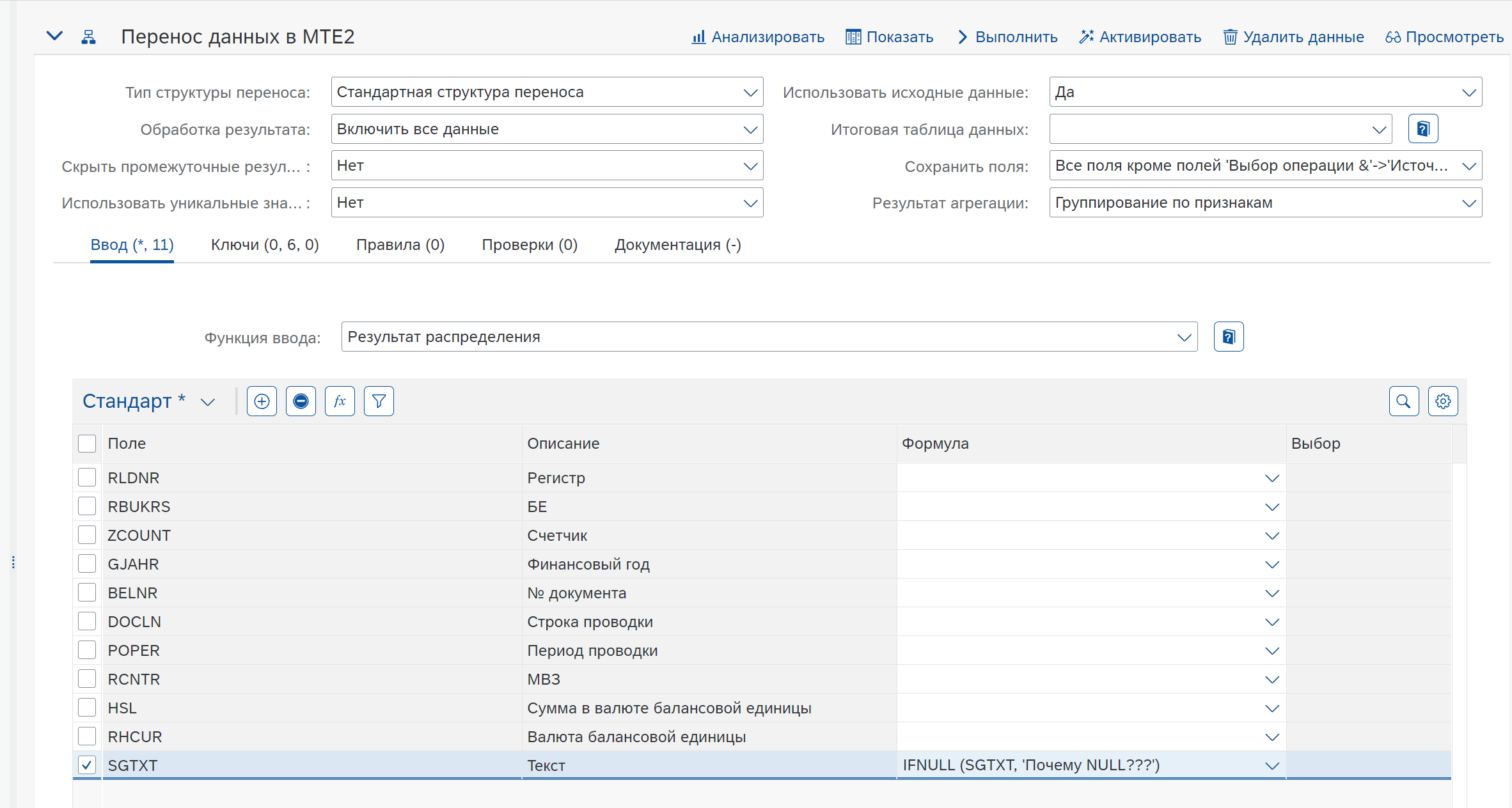
Тогда ошибок не будет, а будет вопрос: Почему NULL???
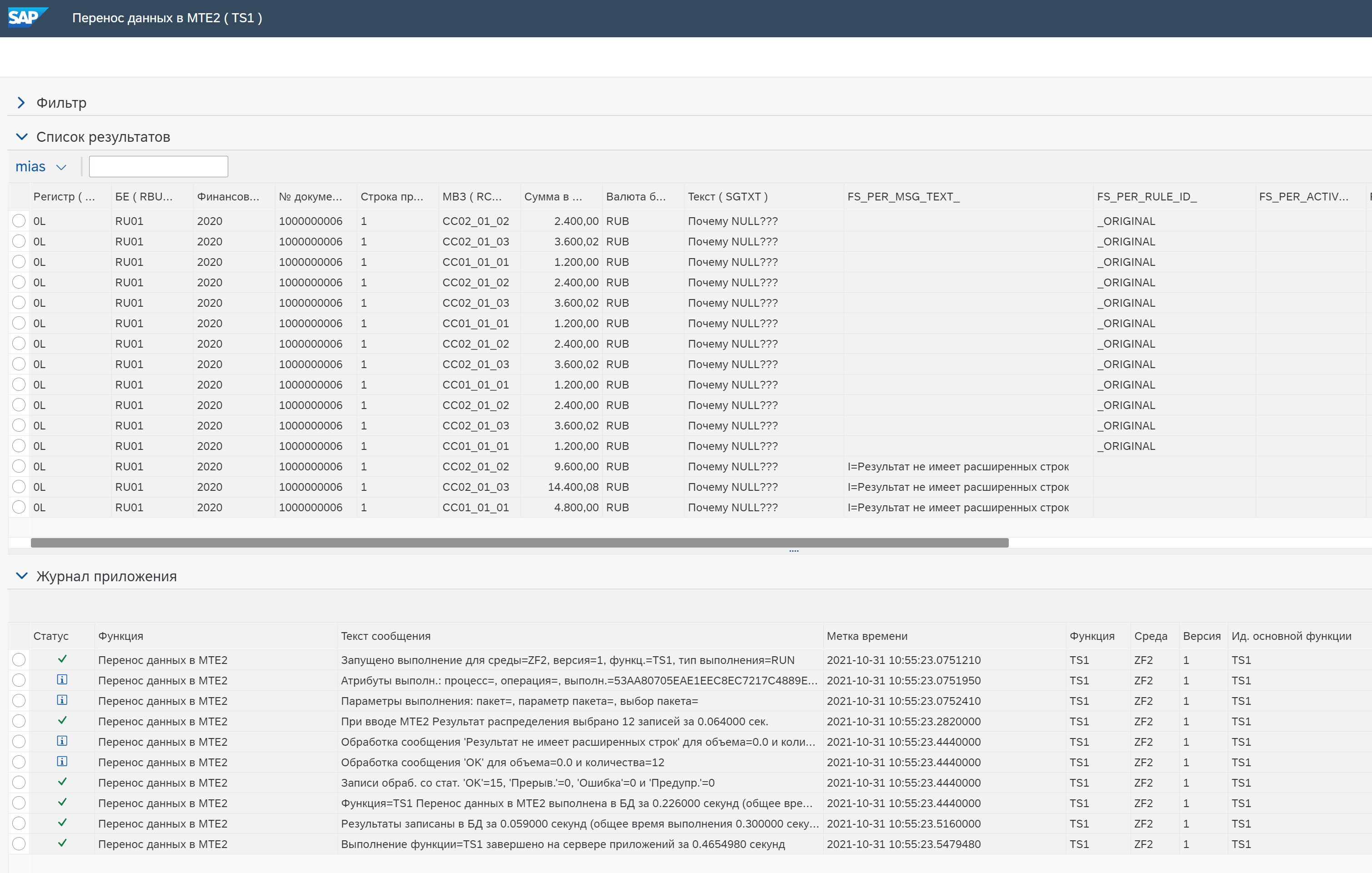
Обработка результата (Result Handling)
Значение: Включить обогащенные данные/Включить все данные/Ошибка в необогащенных данных/Прерывание в случае необогащенных данных
Включить обогащенные данные — включает в результат только записи данных, к которым было применено правило. В конце работы функции, если есть записи данных, для которых система не смогла применить правило, она записывает предупреждение в журнал сообщений.
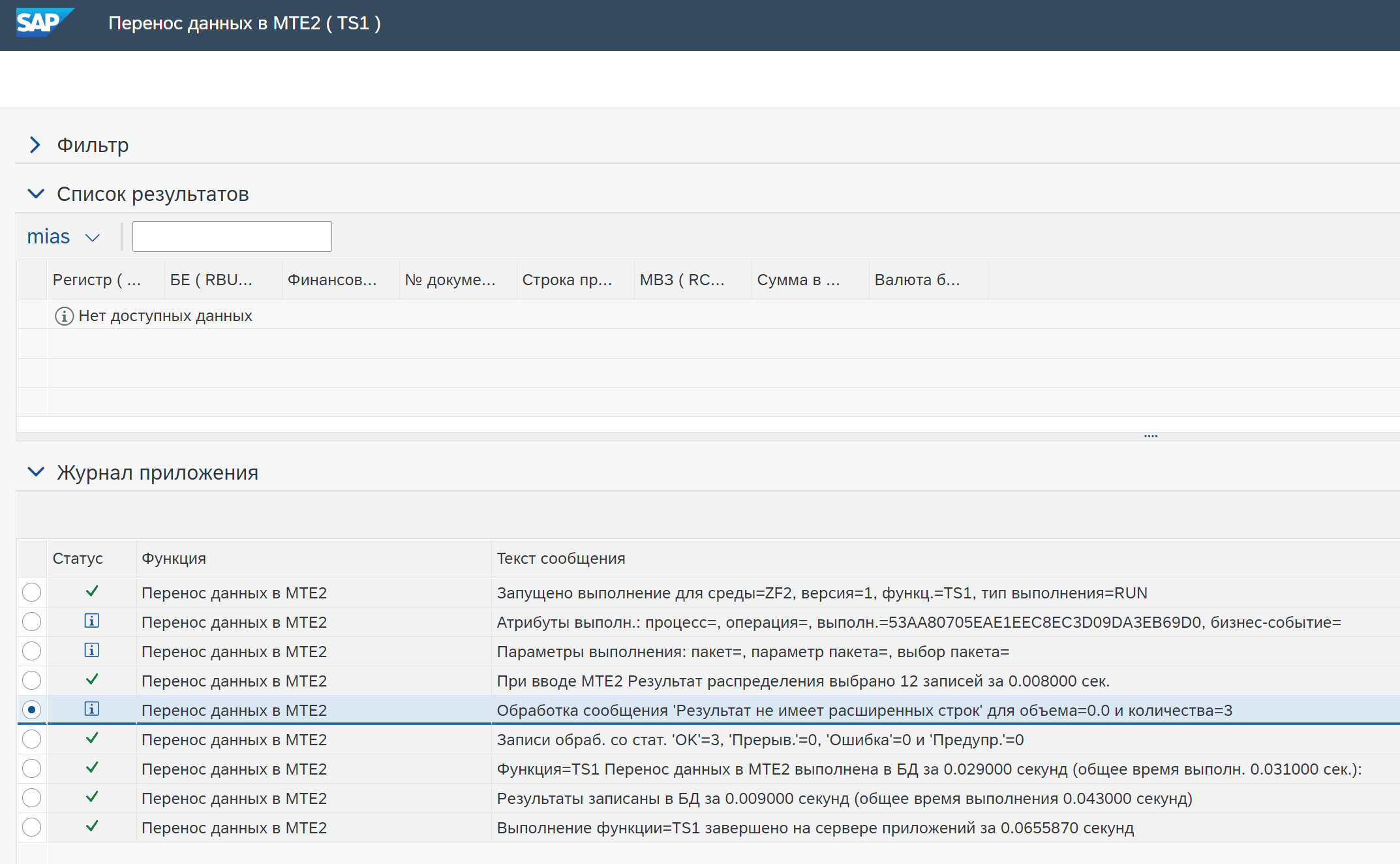
Пример с пустым списком результатов.
Включите все данные — включает все записи данных в результат, независимо от того, применялось ли правило или нет.
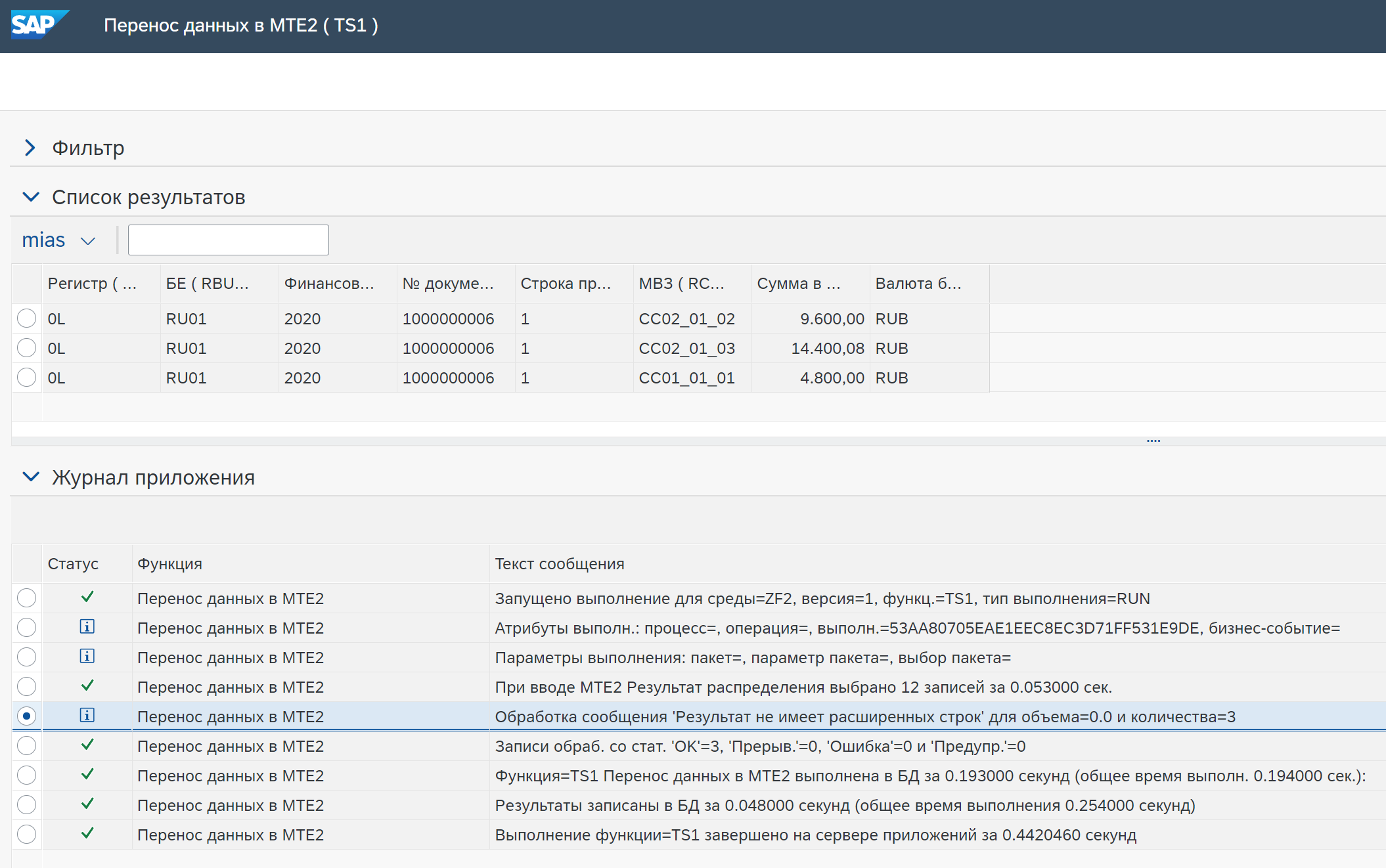
Пример с результатом применения агрегации к исходным данным, согласно настроек функции. Правила функции не применялись.
Ошибка в необогащенных данных — работает так же, как и для включения обогащенных данных. Однако для необогащенных данных подготавливается сообщение об ошибке. Дальнейшая обработка выполняется на основе настройки типа события функции:
- Запись в журнал — ошибка записывается в журнал сообщений.
- Управление — ошибка записывается в журнал сообщений и регистрируется Business event. Бизнес-пользователь может работать с исключительной ситуацией и исправить ее.
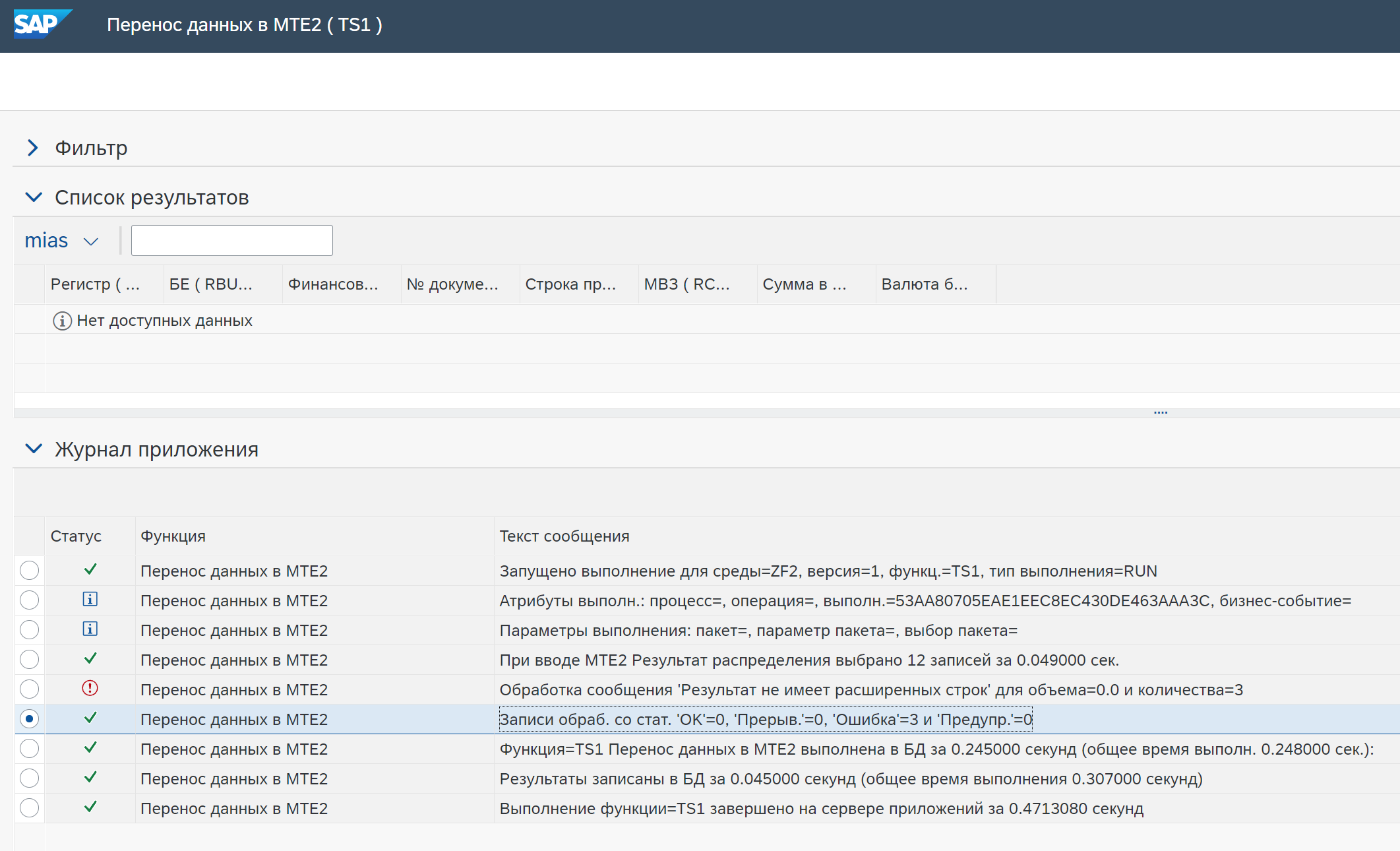
Пример записей в журнале в случае ошибок.
Прерывание в случае необогащенных данных — работает так же, как и ошибки в необогащенных данных, но вместо сообщения об ошибке система записывает в журнал сообщение о прерывании, и функция завершается.

В данном случае было Прерывание.
Скрыть промежуточные результаты (Suppress initial Results)
(Некорректный перевод, причем тут промежуточные результаты!?)
Значение: Да/Нет.
Если выбрать “Да”, результаты, которые содержат только начальные значения в полях Действие (см. вкладку Ключи), например, значение показателя 0 или значение признака ”, будут исключены из выходных данных. Если «пустые» записи результатов не влияют на итоговый результат расчетов, это может уменьшить объем данных и обработку ненужных записей.
Использовать уникальные значения (Ensure Distinct Result)
Если значение Нет, то при наличии нескольких правил

в результате выполнения функции будет несколько результирующих строк для одной первоначальной строки.

В данном случае сработали 3 правила и одна строка превратилась в 3 строки с разным заполнением полей, согласно правил.
Если значение Да, то будет выведена одна строка для первого правила.
Итоговая таблица данных (Result Model Table)
Если таблица модели не назначена, функция выполняется непосредственно в среде моделирования. Результаты сохраняются во временной таблице для конкретной функции. В противном случае результаты функции сохраняются в таблице модели.
Сохранить поля (Retain Fields)
Если в поле Сохранить поля выбрать Все поля кроме полей ‘Выбор операции &’->’Источник’ (All Fields except Selection & Action->Source Fields) то будут сохранены все поля, используемые в этой функции, за исключением полей, определенных на вкладке “Правила” > “Правило” > “Выбор”, и полей источника, используемых в разделе “Действие”.
Если в поле Сохранить поля выбрать Все поля (All Fields), то система использует все поля.
Результат агрегации (Aggregate Result)
Группирование по признакам: показатели автоматически агрегируются с использованием всех входных признаков (за исключением полей в разделе Выбор на вкладке Ключи) в качестве полей группировки.

В хранимой процедуре, которую генерит функция при активации, GROUP BY будет по всем полям-признакам (кроме исключаемых).
Группирование по признакам и показателям: показатели автоматически агрегируются с использованием всех исходных признаков и показателей в качестве полей группировки (за исключением полей в разделе Выбор на вкладке Ключи).

В хранимой процедуре, которую генерит функция при активации, GROUP BY будет по всем полям (кроме исключаемых), в том числе по показателям (HSL).
Без группирования: агрегирование не происходит.
Структура переноса (Transfer Structure) в PaPM: Вкладки
Правила
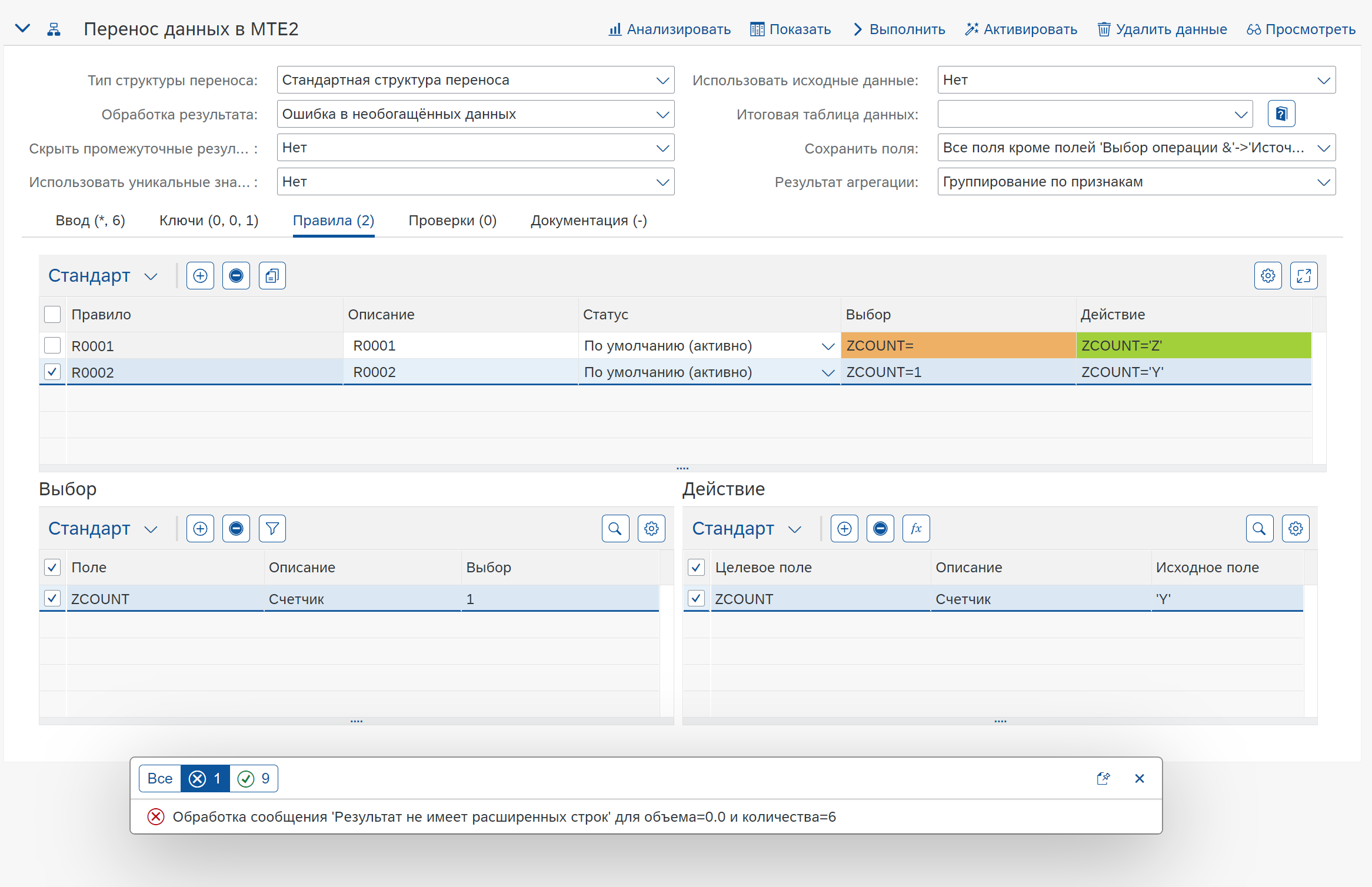
Каждое правило структуры переноса семантически определяет оператор if-then. Часть if выбирает, к какому подмножеству входных данных относится правило. Затем часть представляет собой действие и содержит список полей и значений, которые необходимо назначить.
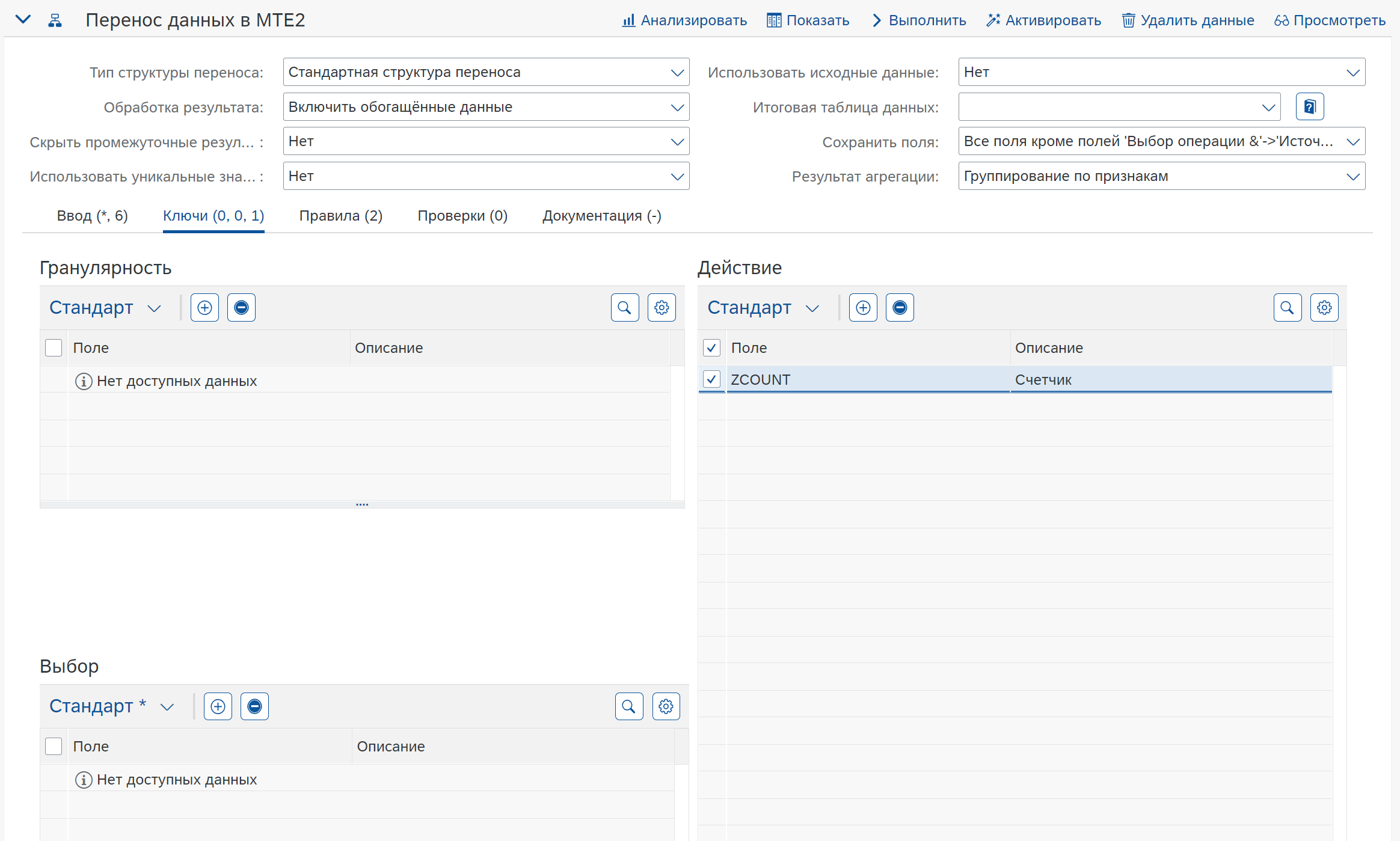
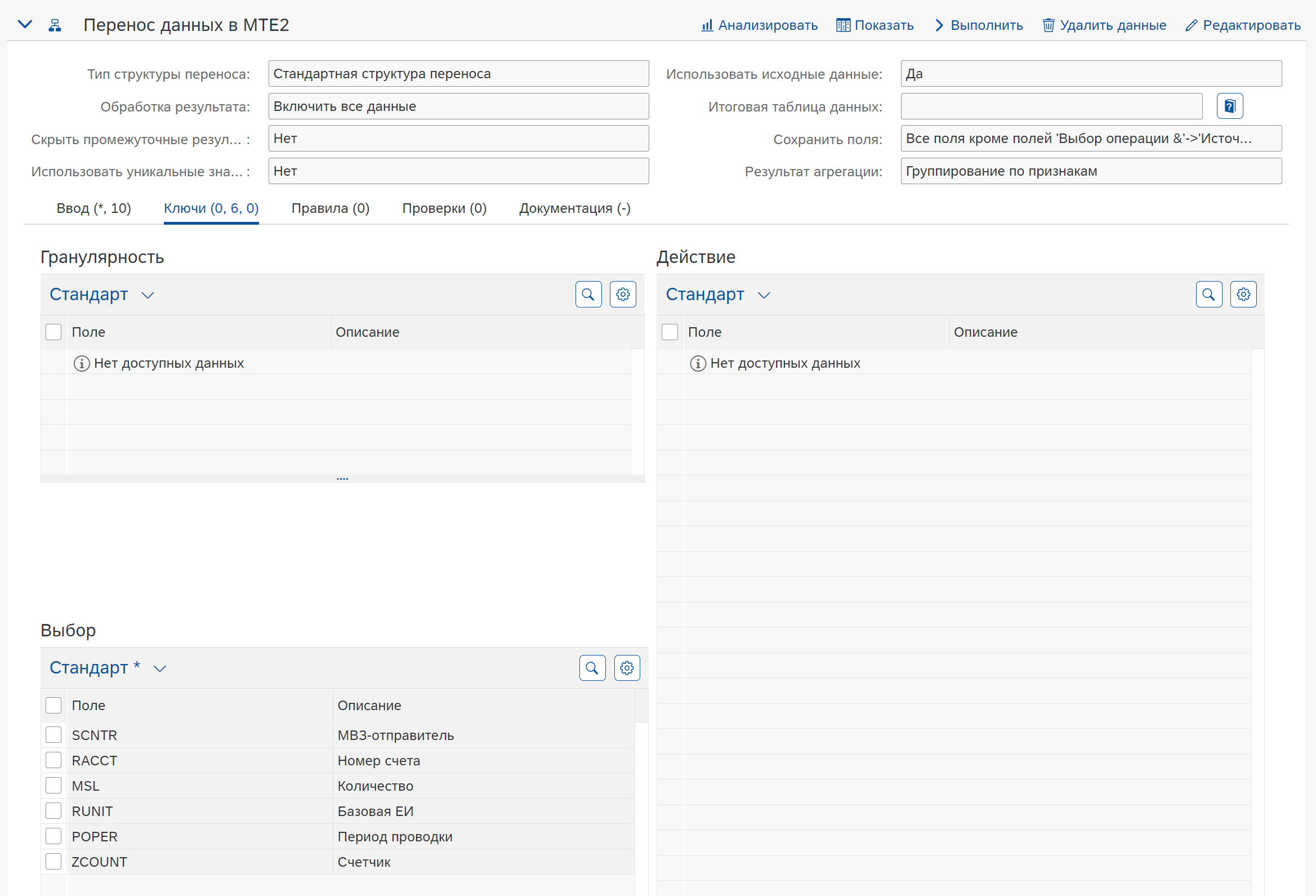
В данном случае поле ZCOUNT участвует в агрегации, так как не находится в разделе Выбор.
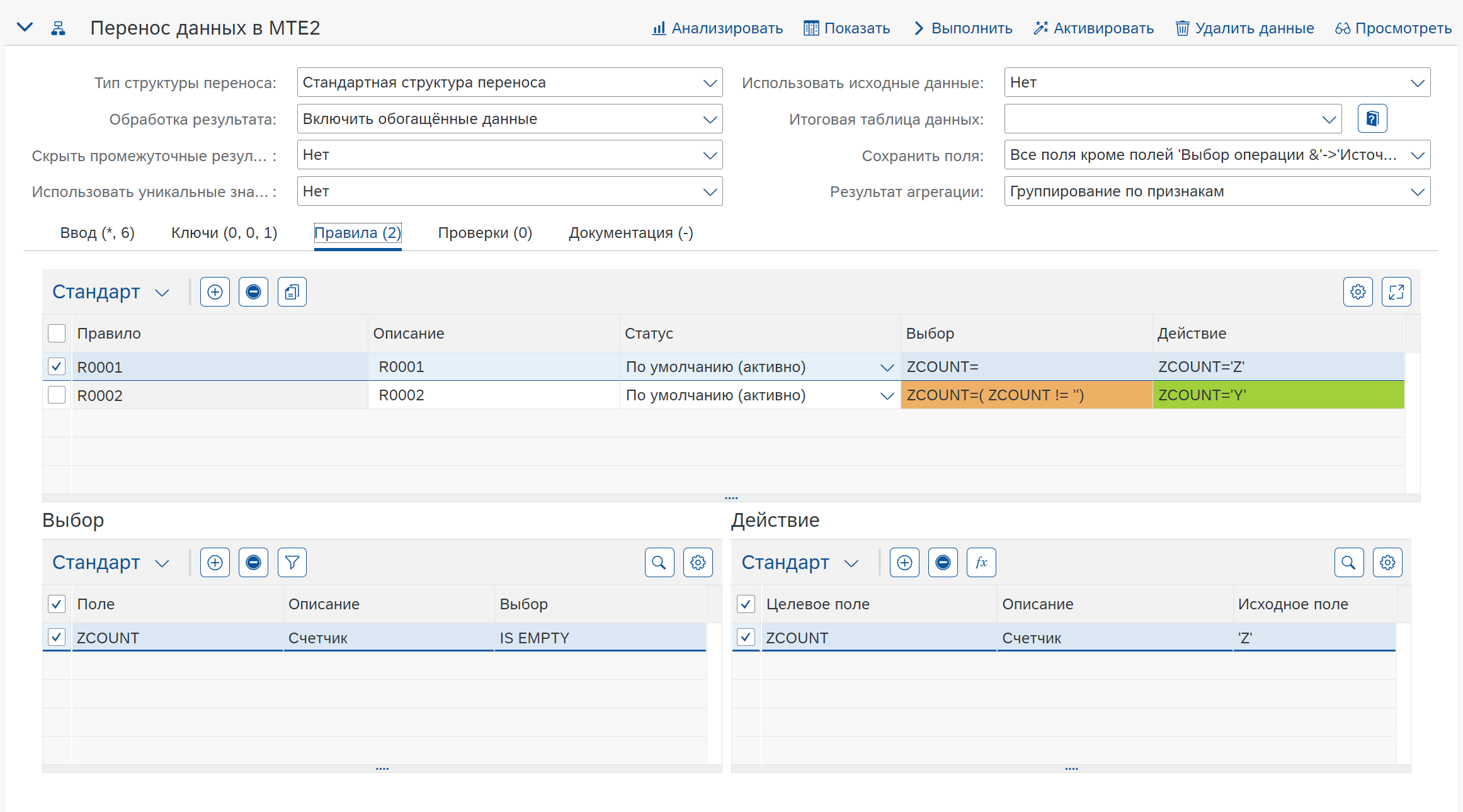
Два правила обеспечивают логику заполнения полей новыми значениями, в результате после агрегации будет следующий результат:
Если правило не будет применено к какой-то записи и в заголовке функции Обработка результата = Ошибка в необогащенных данных, то будет ошибка: