Распределение (Allocation) в PaPM – используется для распределения ключевых показателей от отправителя к получателю с использованием базы распределения.
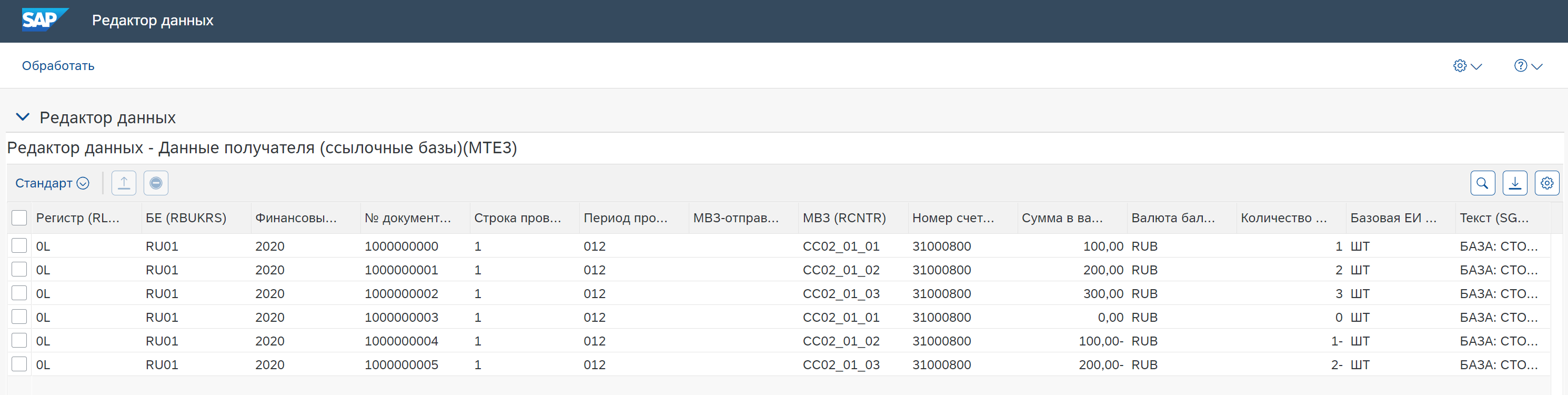
Для примера возьмем распределение затрат дебета МВЗ по базе, которая состоит из проводок по счетам на разные другие МВЗ (например, затраты склада нужно распределить по базе стоимостей материалов, которые были списаны с этого склада на разные другие МВЗ). Имеем следующие упрощенные таблицы с данными для распределения и ссылочными базами:

Данные отправителя для распределения

Данные получателя с ссылочным базами.
В данном случае номер документа (BELNR) играет роль признака, который нужно “протащить” через распределение, то есть распределенные итоговые суммы должны содержать номер документа из исходных данных для распределения. А записи с нулевыми суммами (HSL) добавлены для демонстрации некоторых опций функции распределения.
Эти данные загружены в функции с Типом функции = Таблица Модели и с Источником таблицы модели = Среда (в данном примере функция таблицы модели MTE1 “Данные отправителя для распределения” и MTE3 “Данные получателя (ссылочные базы)”), то есть мы можем редактировать эти данные прямо в среде PaPM.
Почему две таблицы? Во-первых, не хочется указывать критерии выбора для разделения данных отправителя и получателя в случае когда данные в одном файле. Критерии формирования данных отправителей и получателей вне области рассмотрения данного примера.
Во-вторых, и это главное, для сохранения данных получателя в результирующих данных распределения структуры должны быть разными. Дело в том, что при выборе Типа правила = ‘Косвенное детально’, значения полей из структуры отправителя переносятся в поля структуры получателя и данные о МВЗ, для которых были указаны ссылочные базы будут потеряны (в данном примере поле RCNTR). Поэтому поля RCNTR нет в структуре отправителя. Значение в поле RCNTR в результирующих данных расчета будет взять из структуры получателя.
тр. /NXI/P1_MODEL – Запустить мои среды

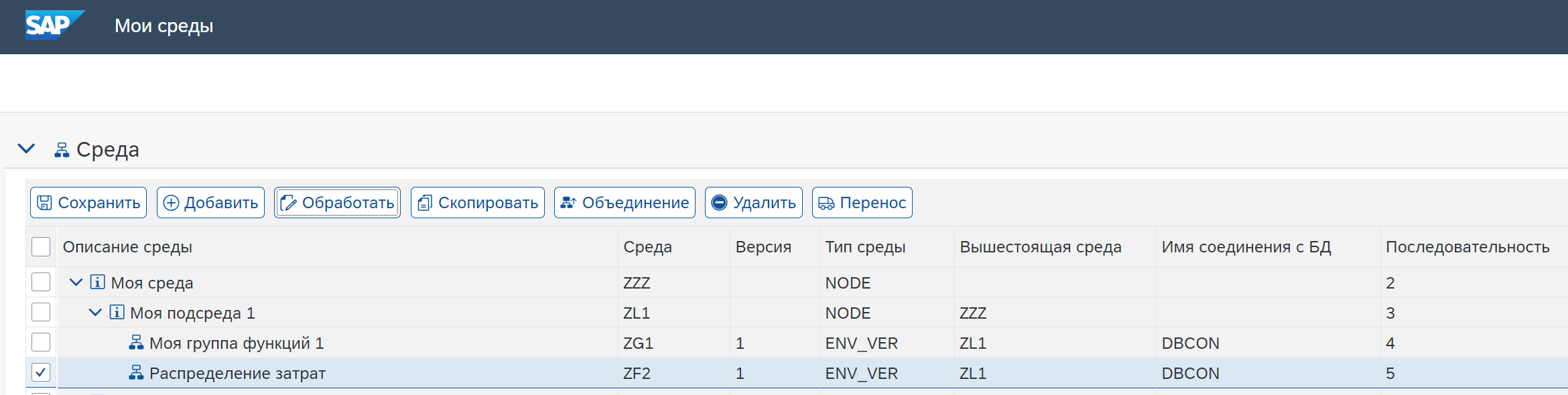
Создаем тестовую среду для примера с распределением
Переходим в режим редактирования, создаем записи с типом “Узел” (для структурирования среды) и запись с типом “Версия среды” для данного примера. Сохраняем.
Выбираем запись с типом Версия среды (в данном случае “Распределение затрат”) и выбираем <Дальше>.
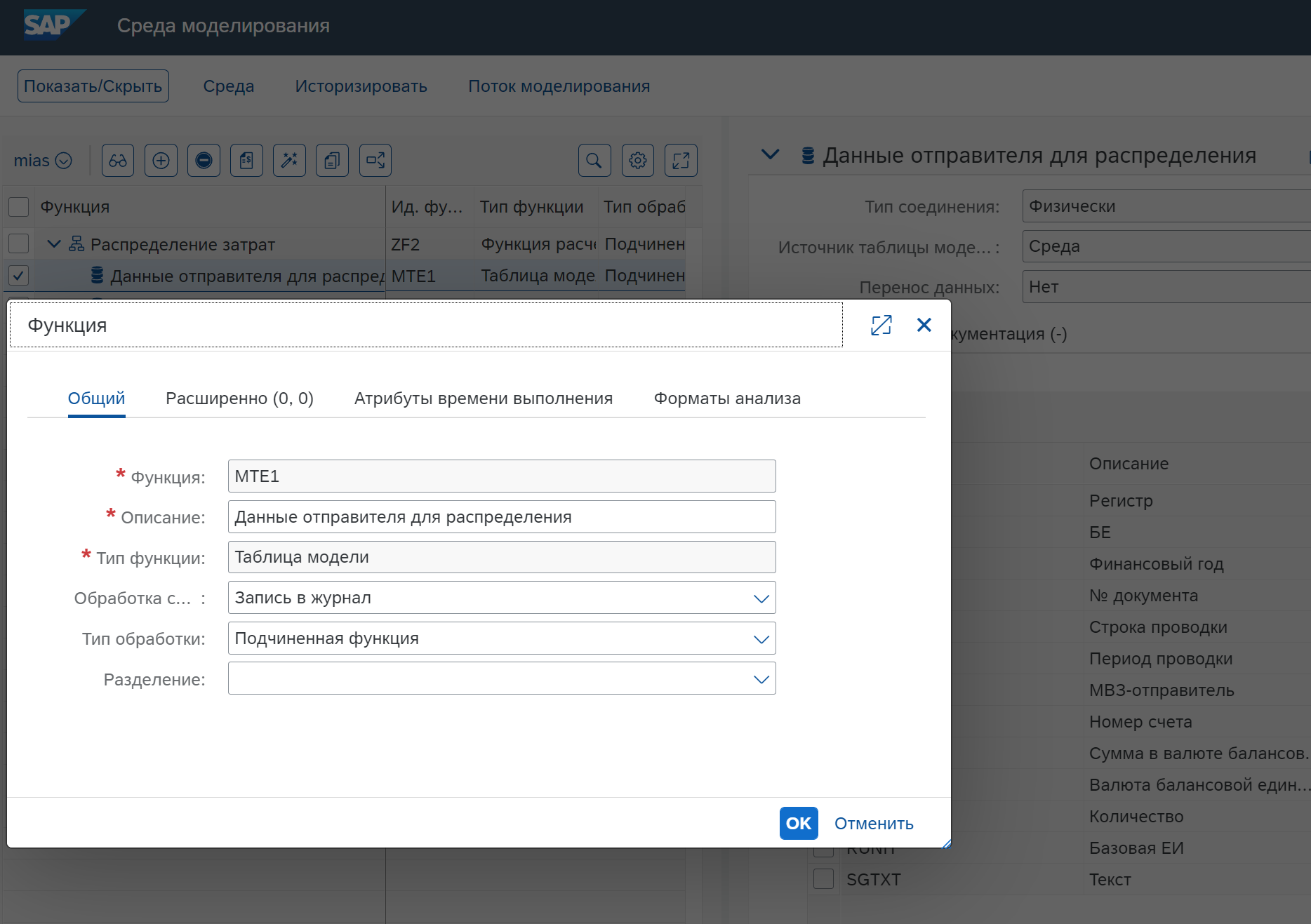
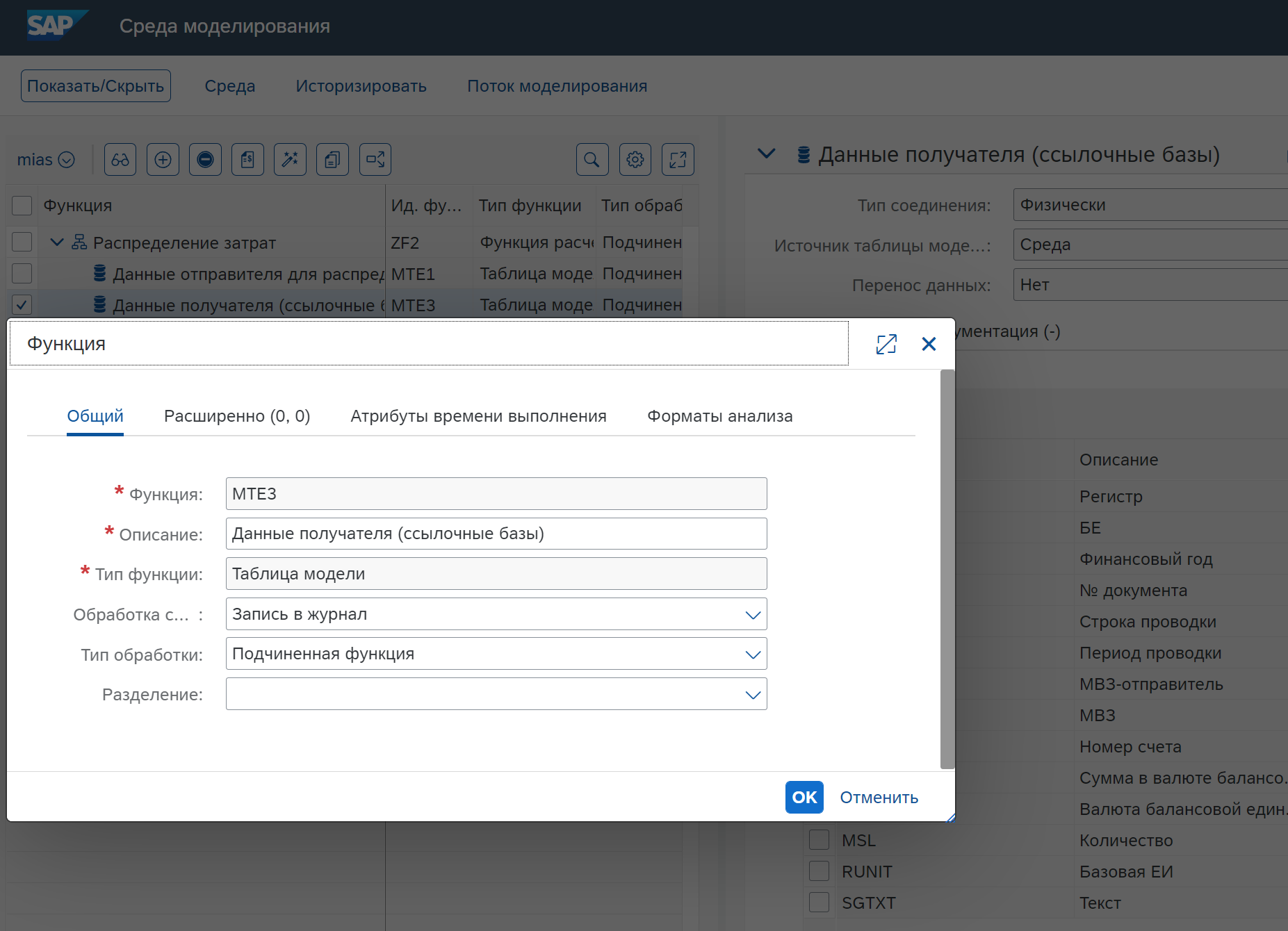
Создаем функции таблицы модели
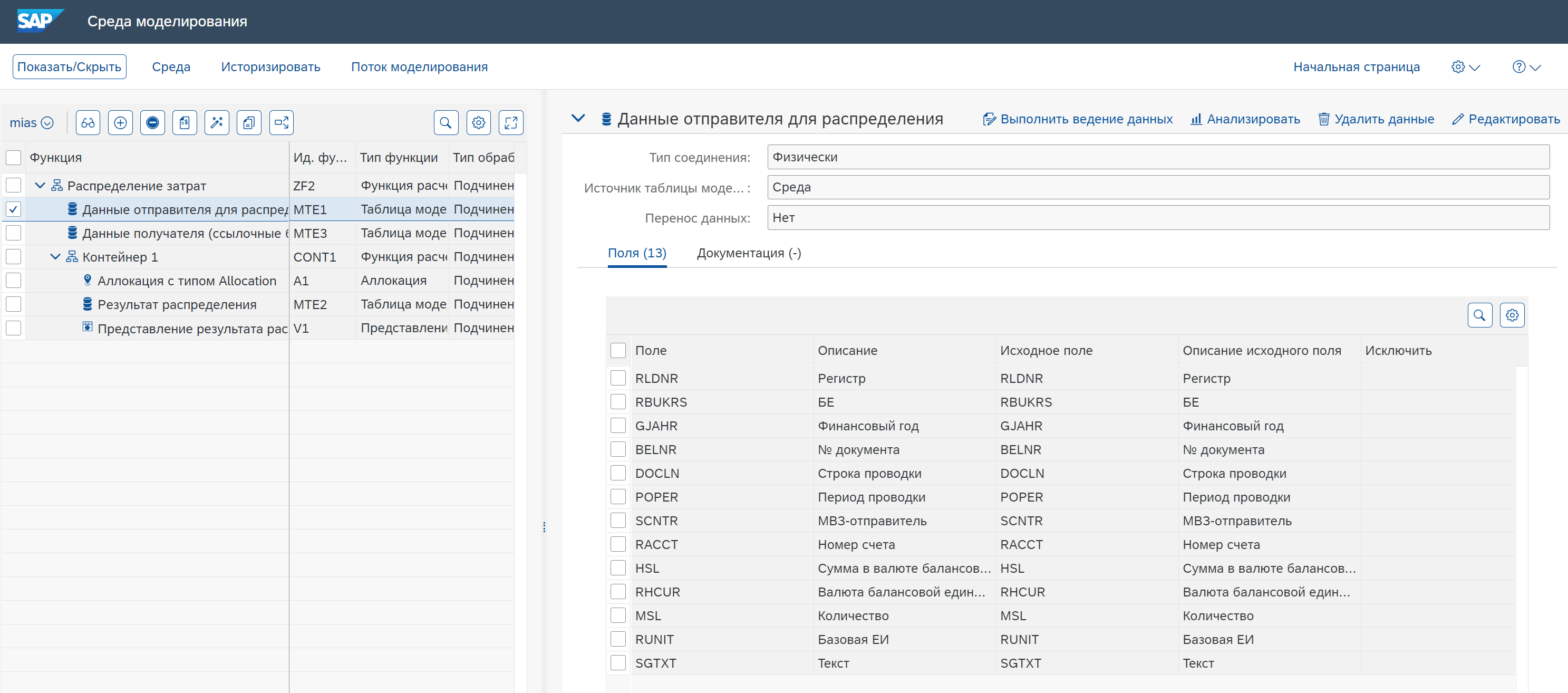
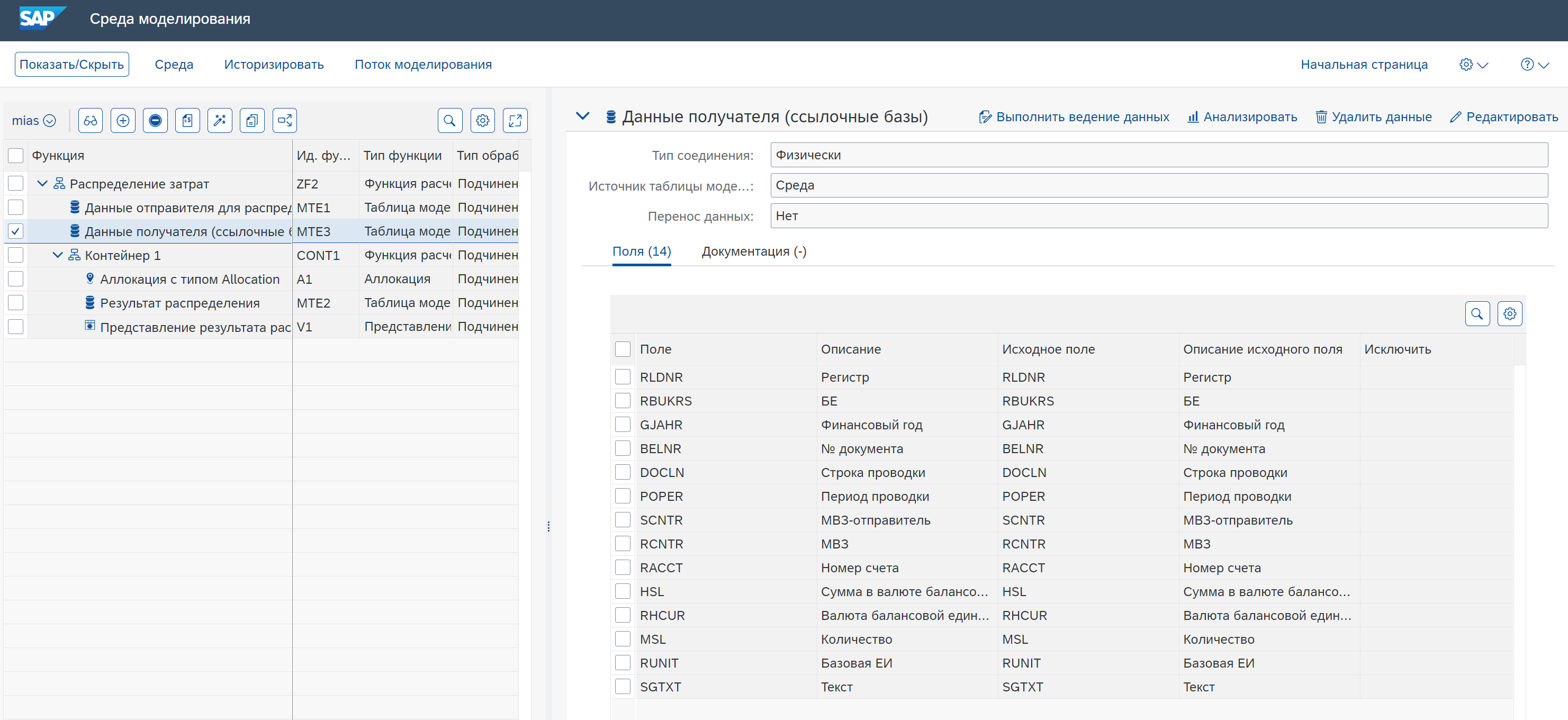
Определяем Тип соединения = Физически и Источник таблицы модели = Среда. Добавляем необходимые поля в режиме редактирования.
Примечание: изначально Среда моделирования пустая, у нее нет метаданных. Для того, чтобы ее наполнить описаниями полей, можно создать функцию таблицы модели и указать Тип соединения = Физически, Источник таблицы модели = Словарь данных, Имя таблицы = ACDOCA (например) и выбрать все поля таблицы. После сохранения функции в Среде моделирования появятся метаданные, которые уже потом можно использовать для создания своих функций таблицы модели.

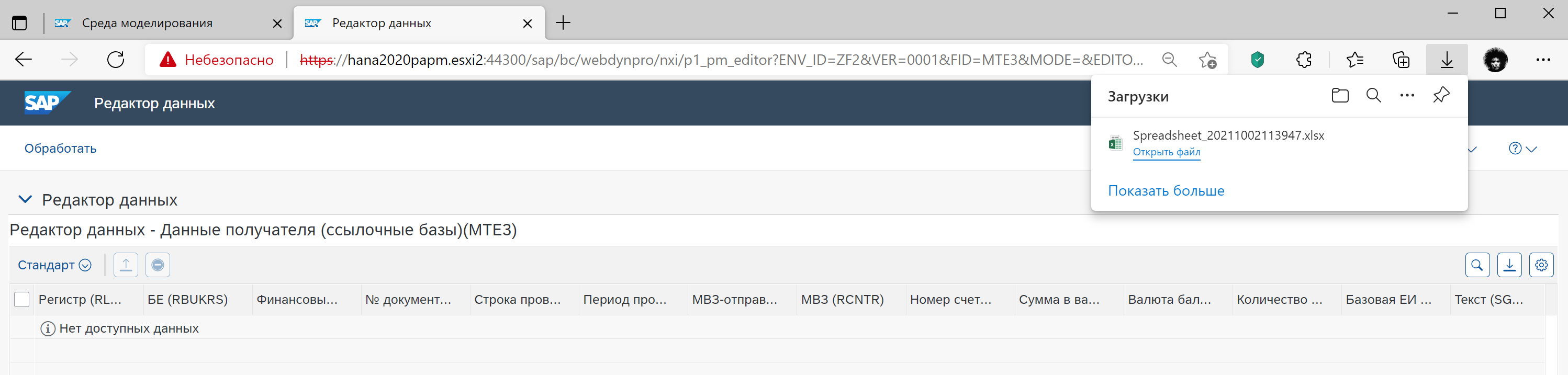
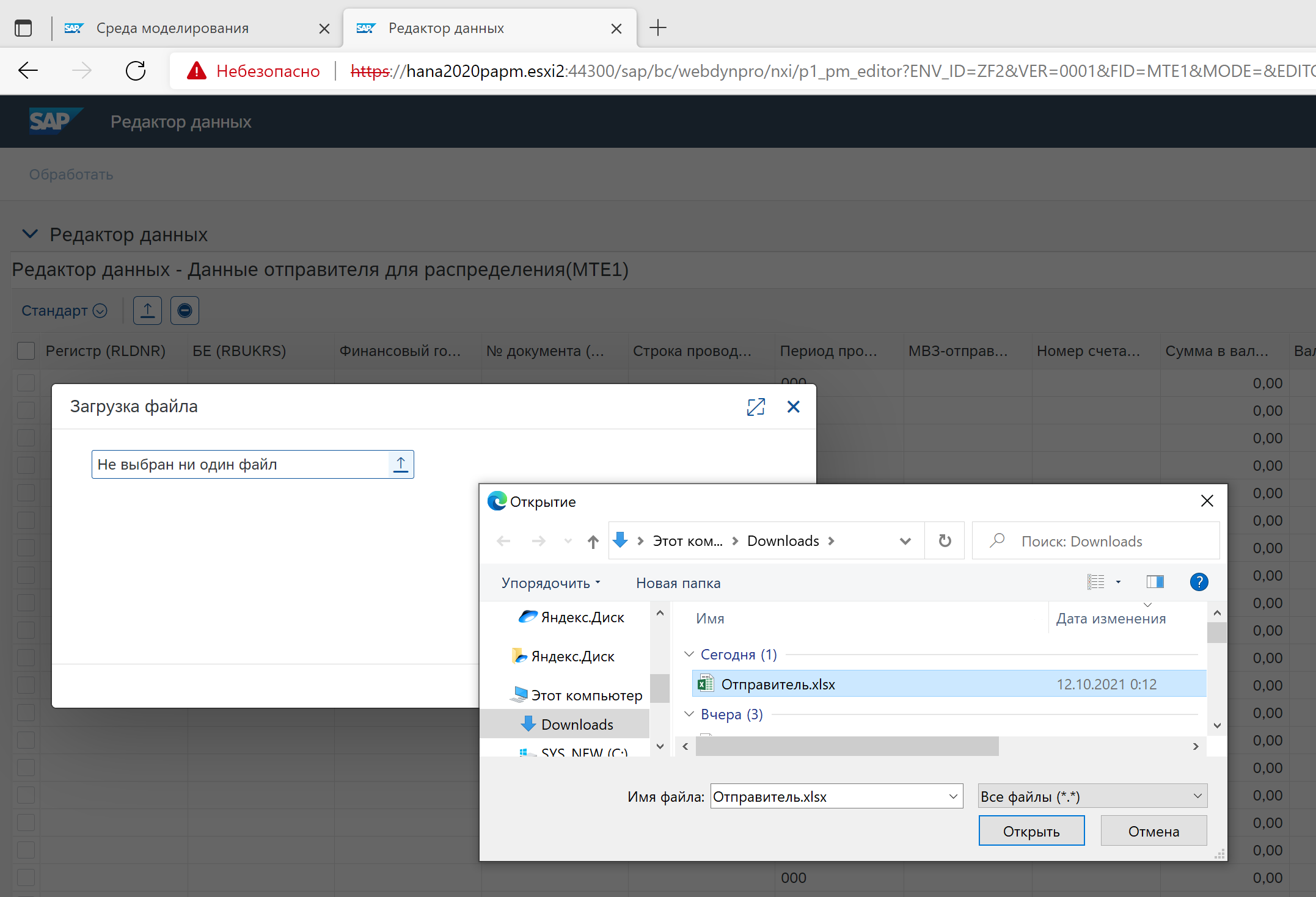
После создания функции выбираем <Выполнить ведение данных> и выбираем <Экспорт в электронную таблицу>. Далее заполняем Excel необходимыми для примера данными и загружаем обратно. Преимущество выгрузки в том, что формируется Excel с нужной структурой и существующими в таблице среды данными.

Получаем таблицу среды с данными для тестов:

Создаем функцию распределения
Создаем функцию с Типом функции = Аллокация, предварительно создав функцию с Типом функции = Функция расчета как контейнер, в котором будут проводится расчеты, хотя это и не обязательно, сама запись с типом Версия среды, созданная на предыдущем экране, станет записью с типом Функция расчета в данной среде моделирования.
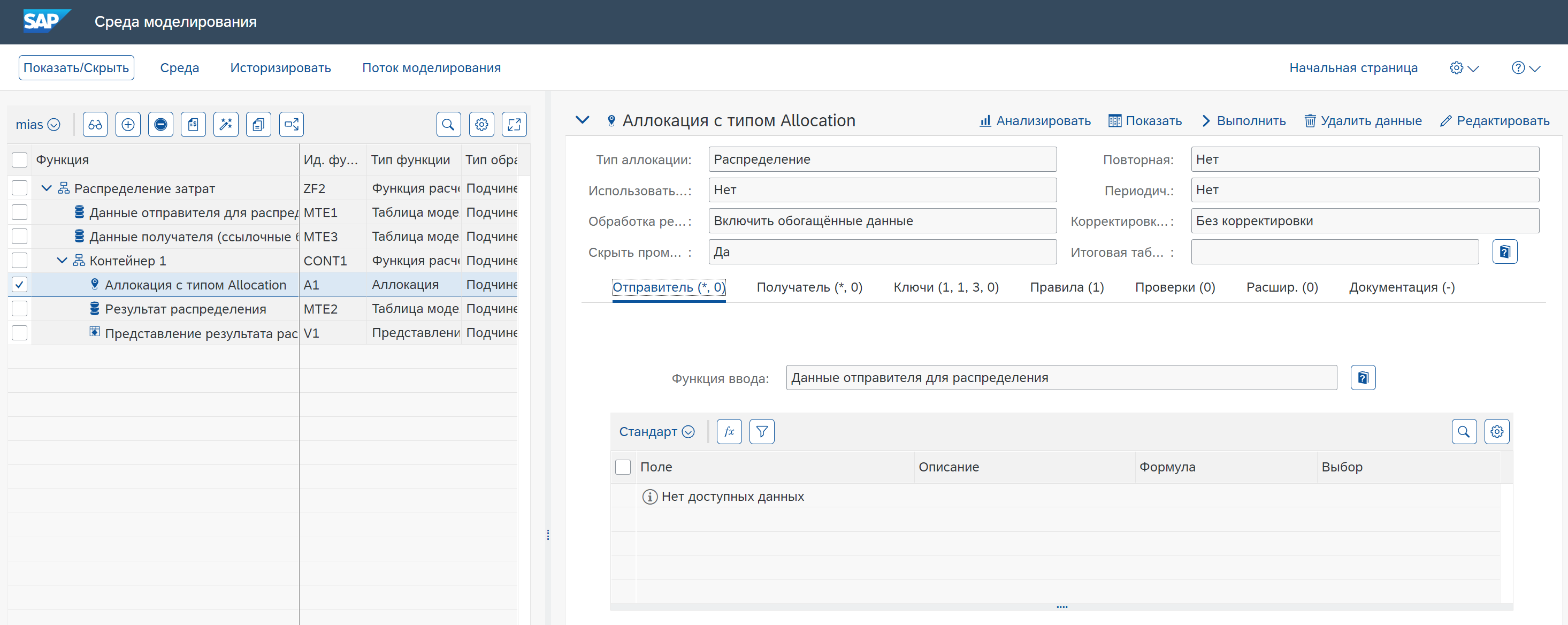
Распределение (Allocation) в PaPM: Заголовок функции
Теперь подробнее про поля заголовка функции:
Использовать исходные данные (Include original Input Data)
Значение: Да/Нет.
Если выбрать “Да”, исходные входные данные (записи) будут добавлены к выходным данным (записям) вместе с полученными результатами. Это облегчает моделирование требований в тех случаях, когда один сценарий строится поверх другого, и поэтому необходимо сохранить исходные результаты сценария и добавить к ним дополнительные результаты.
Обработка результата (Result Handling)
Значение: Включить обогащенные данные/Включить все данные/Ошибка в необогащенных данных/Прерывание в случае необогащенных данных
Включить обогащенные данные – включает в результат только записи данных, к которым было применено правило. В конце работы функции, если есть записи данных, для которых система не смогла применить правило, она записывает предупреждение в журнал сообщений.

Пример с пустым списком результатов.
Включите все данные – включает все записи данных в результат, независимо от того, применялось ли правило или нет.

Пример с необработанными записями отправителя.
Ошибка в необогащенных данных – работает так же, как и для включения обогащенных данных. Однако для необогащенных данных подготавливается сообщение об ошибке, и дальнейшая обработка выполняется на основе настройки типа события функции:
- Запись в журнал – ошибка записывается в журнал сообщений.
- Управление – ошибка записывается в журнал сообщений и регистрируется Business event, чтобы бизнес-пользователь мог работать с исключительной ситуацией и исправить ее.
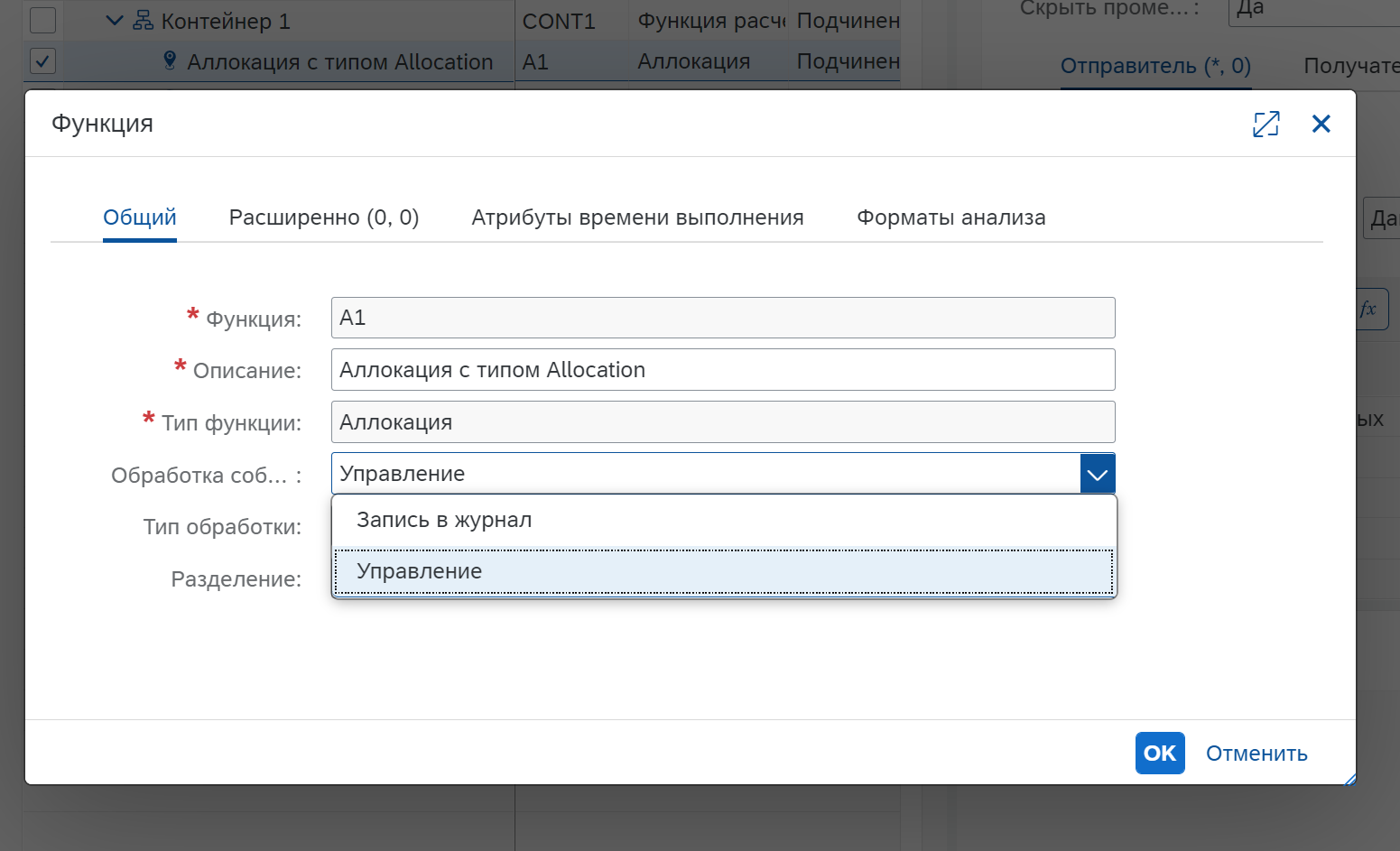

Пример записей в журнале в случае ошибок.
Прерывание в случае необогащенных данных – работает так же, как и ошибки в необогащенных данных, но вместо сообщения об ошибке система записывает в журнал сообщение об отмене, и функция завершается.

В данном случае было Прерывание.
Скрыть промежуточные результаты (Suppress initial Results)
(Некорректный перевод, причем тут промежуточные результаты!?)
Значение: Да/Нет.
Если выбрать “Да”, результаты, которые содержат только начальные значения (например, значение показателя 0 или значение признака ”), будут исключены из выходных данных. Если “пустые” записи результатов не влияют на итоговый результат расчетов, это может уменьшить объем данных и обработку ненужных записей.
Итоговая таблица данных (Result Model Table)
Если таблица модели не назначена, функция выполняется непосредственно в среде моделирования, а результаты сохраняются во временной таблице для конкретной функции. В противном случае результаты функции сохраняются в таблице модели.
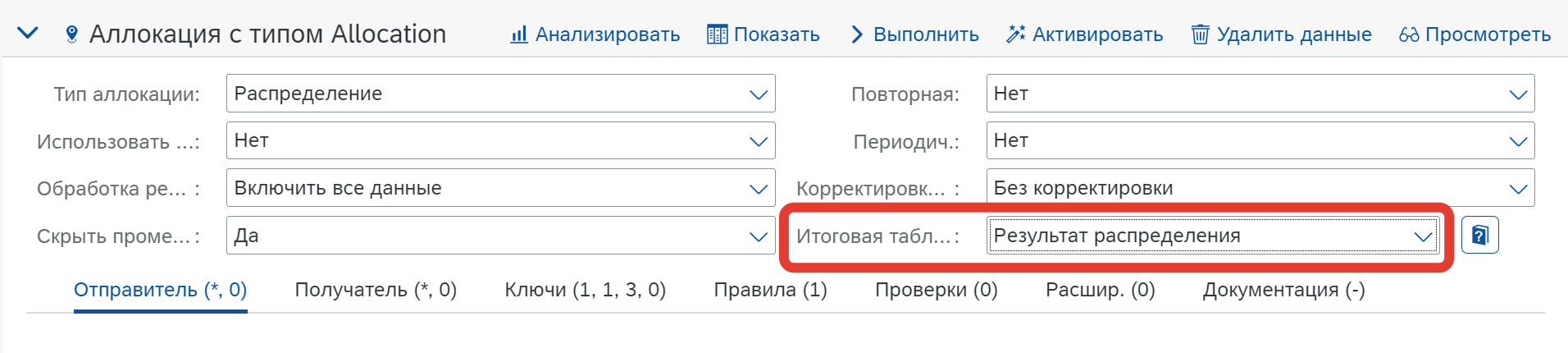

При этом есть особенность:
Если функция распределения выполняемая, то есть в настройках типа обработки функции указано “Выполняемый”, то при использовании функции распределения как входящей функции для какой-то другой функции, при запуске этой какой-то другой функции таблица модели для результатов, указанная в функции распределения, будет заполнена.

Функция распределения A1 имеет в качестве Итоговой таблицы данных функцию MTE2 (таблица модели с типом Среда) и является выполняемой. Функция представления V1 имеет в качестве функции ввода функцию A1. При запуске функции V1 на выполнение, система запишет данные в таблицу MTE2. Если бы функция A1 не была выполняемой, то данные в таблицу среды не записались бы.
Если запускать саму функцию распределения A1, то независимо от того, выполняемая она или подчиненная, записи в таблицу результата будут записаны в любом случае.
Тип аллокации
Распределение – то, что мы видели до этого. примеры выше сделаны с данным типом аллокации.
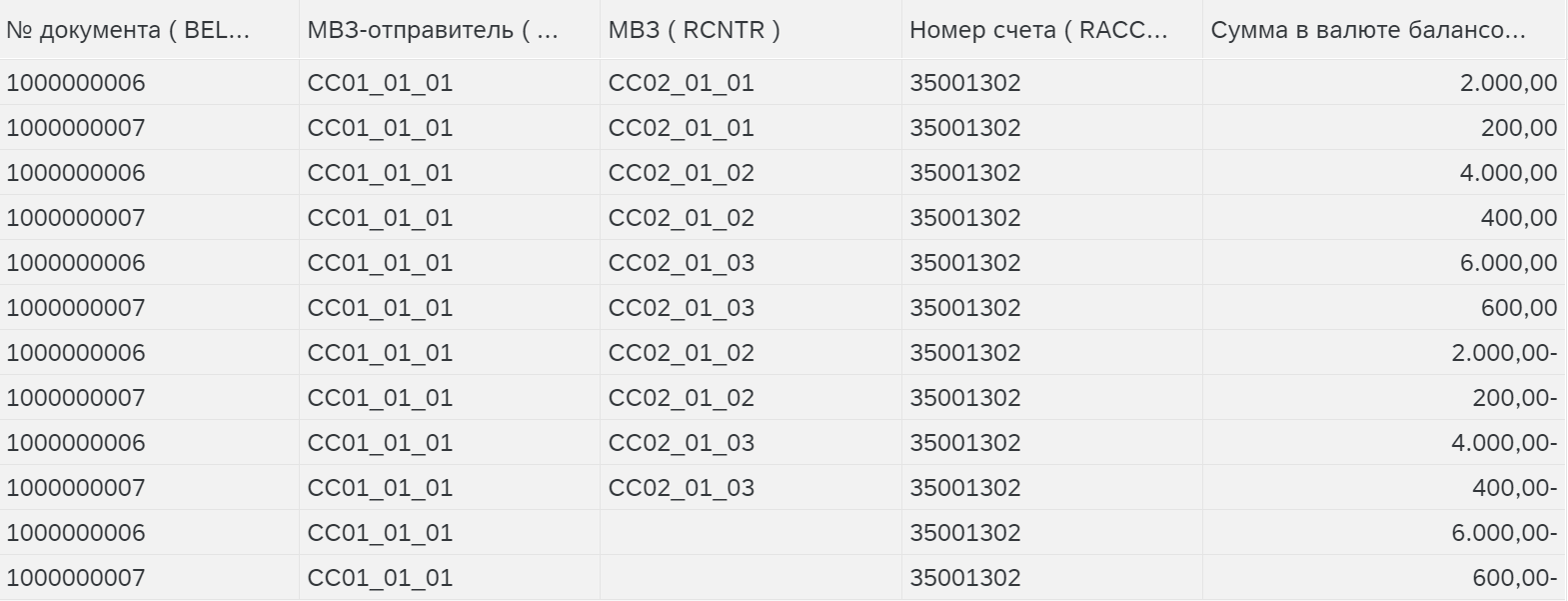
Аллокация с записями смещения – создает запись на минус того, что было распределено (некое сторно значений отправителя).
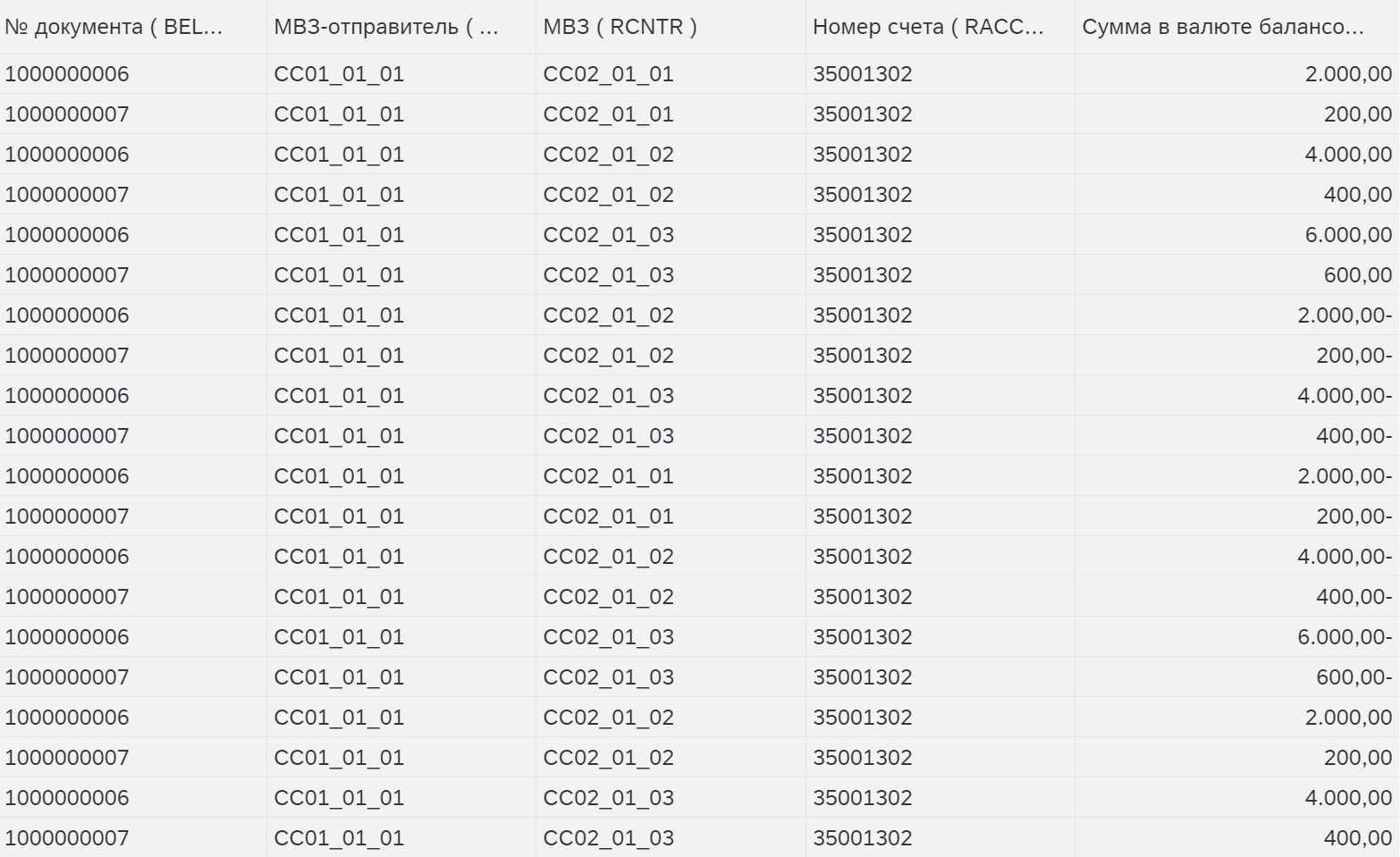
Аллокация с подробными записями смещения – создает детальные записи на минус (сторно).
Распределение (Allocation) в PaPM: Вкладки
Отправитель (Sender)
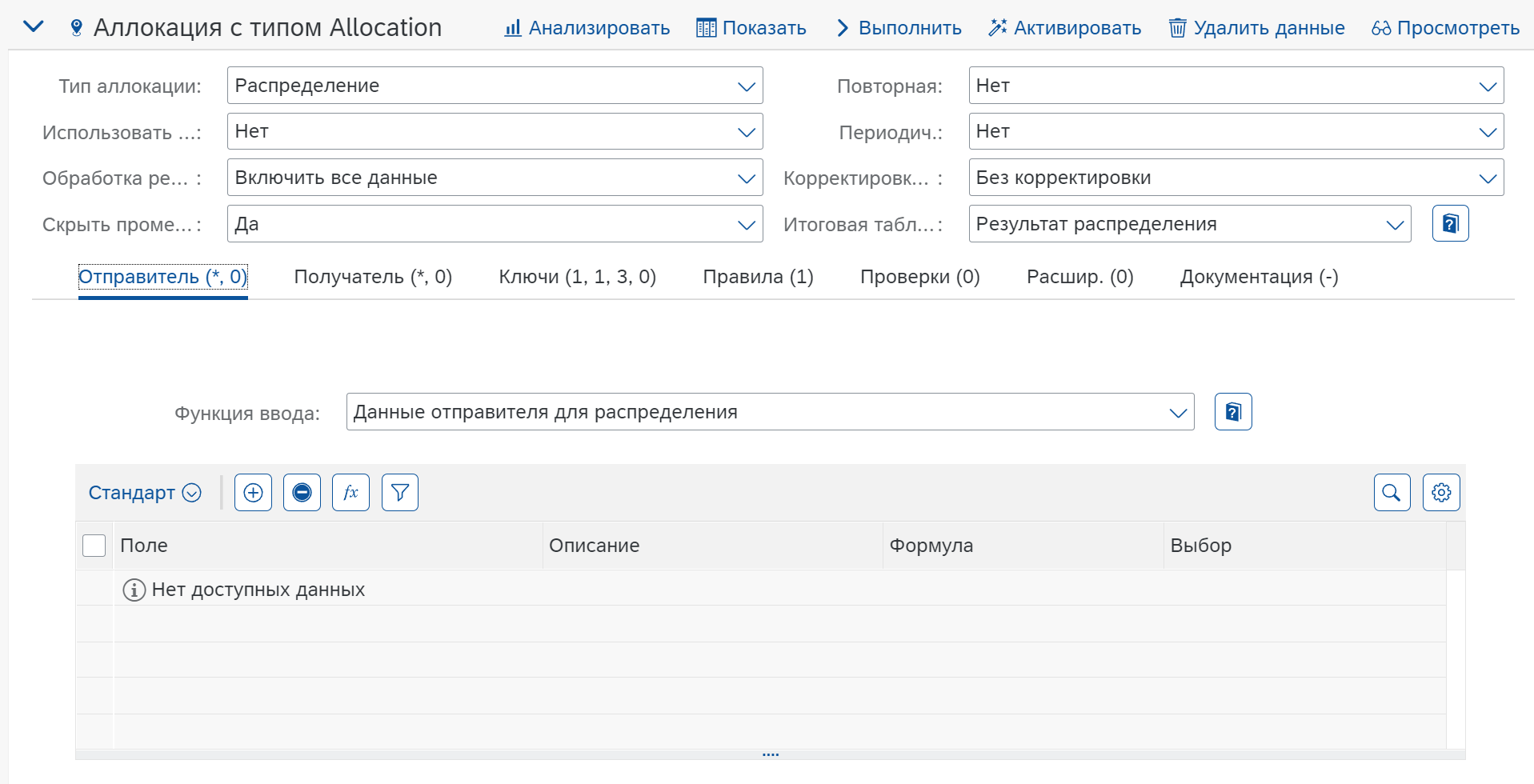
Указываем функцию таблицы модели MTE1 “Данные отправителя для распределения” в которой содержатся позиции для распределения.
Получатель (Receiver)
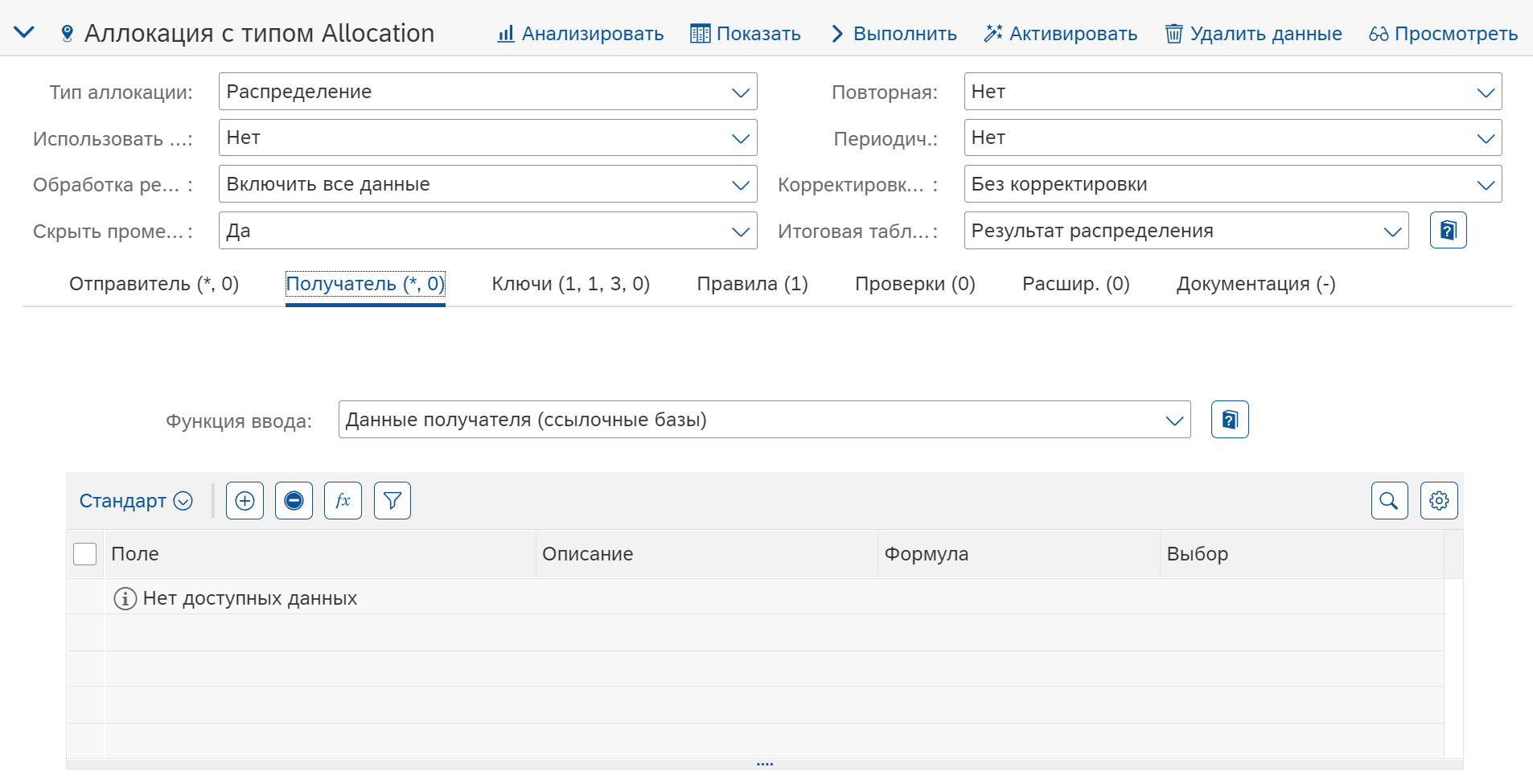
Указываем функцию таблицы модели MTE3 “Данные получателя (ссылочные базы)” в которой содержатся позиции как базы для распределения.
Ключи (Signature)
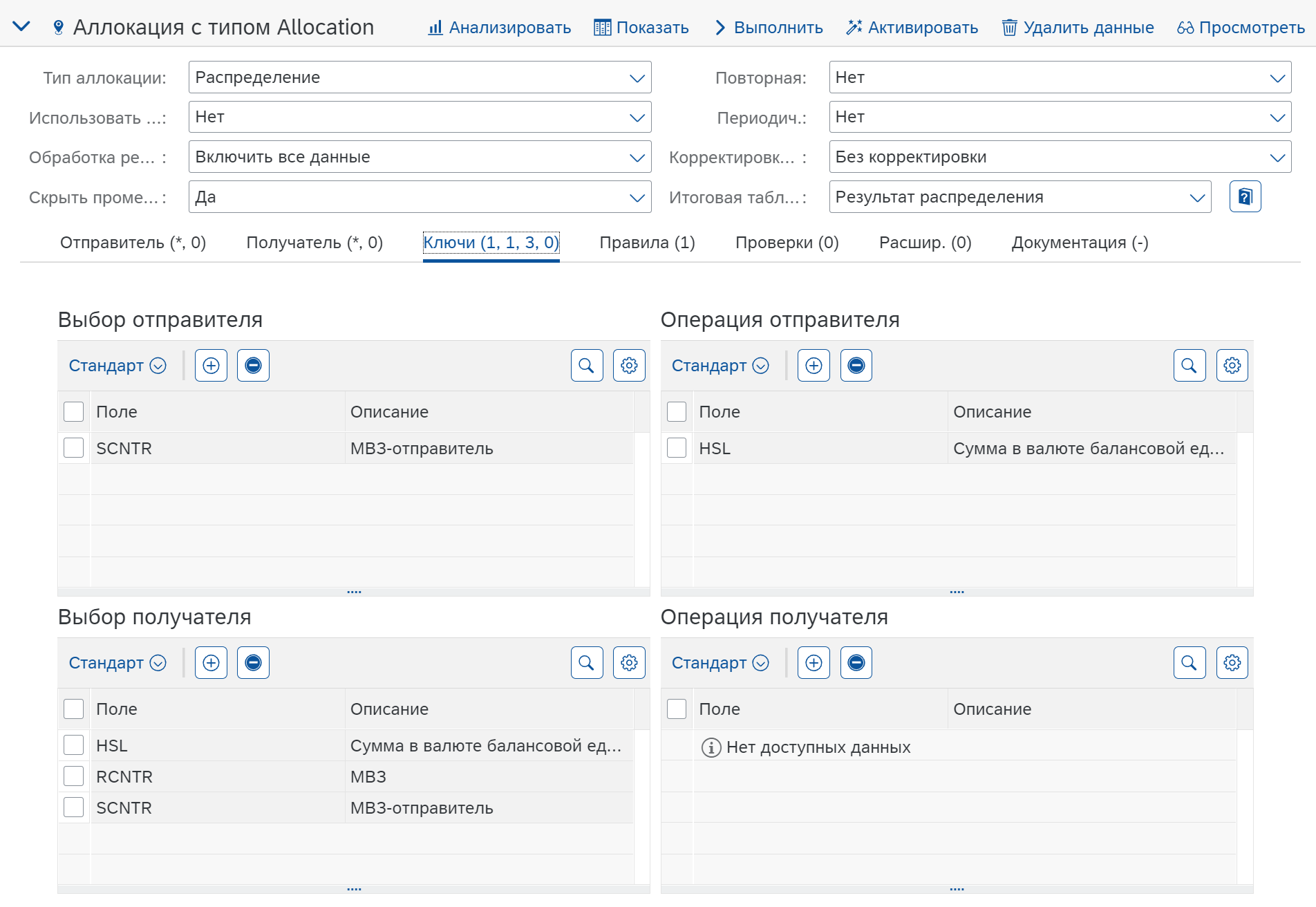
Важно, чтобы в разделе “Операция отправителя” были указаны показатели, которые будут распределятся (в данном случае Сумма во ВВ, которая будет выбрана для конкретного МВЗ). Эти поля (показатели) будут доступны на вкладке “Правила” для выбора в поле “Поля значений отправителей”.
Для получателя указываем Сумма во ВВ (HSL), которые будут использоваться как база для распределения.
МВЗ и МВЗ-отправитель для примера без интерактивного распределения не нужны, эти поля потребуются для примера с циклами распределения.
Правила (Rules)
Правило отправителя:
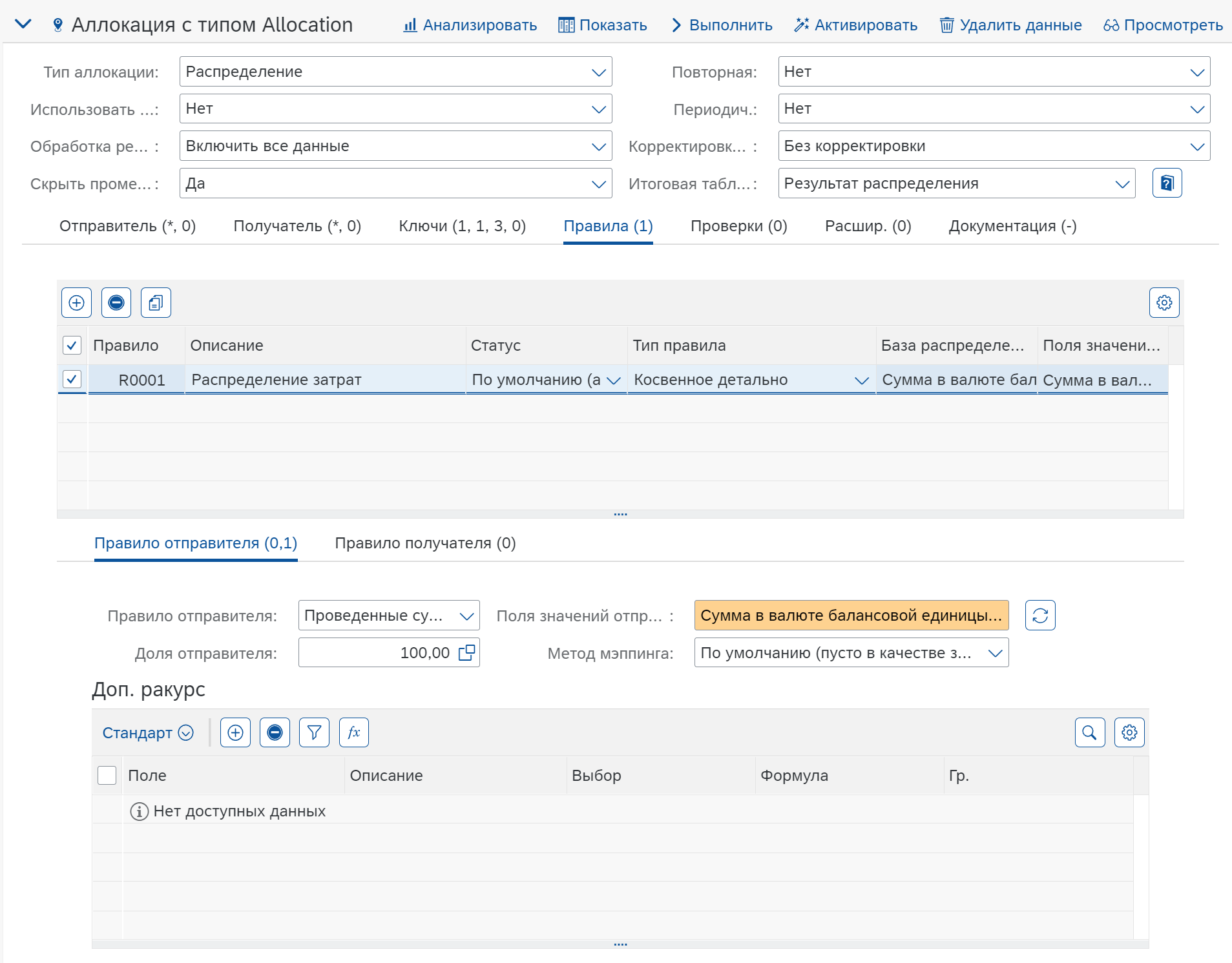
В поле “Поля значений отправителей” выбираем Сумма во ВВ (HSL):
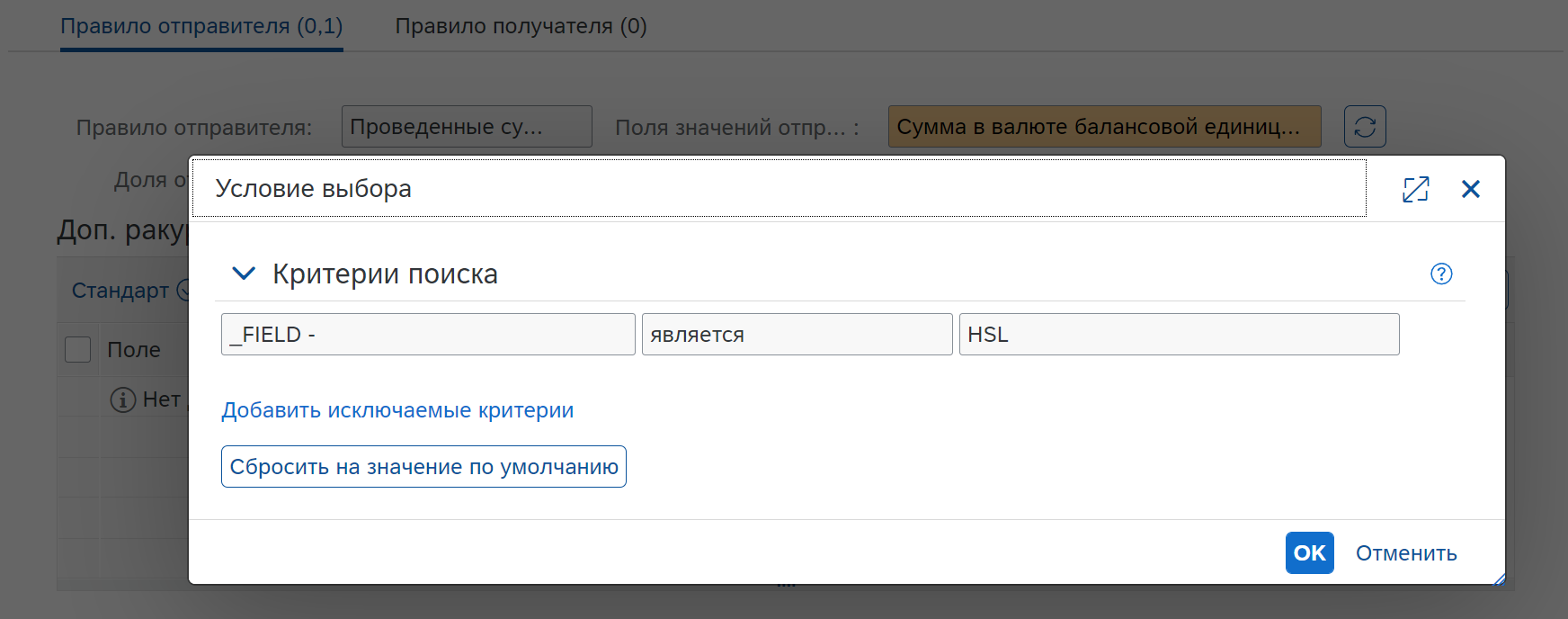
Правило получателя:

Немного подробнее про правила получателя:
Поле Правило получателя:
Переменные части – показатели отправителя (HSL) распределяются пропорционально показателям у записей получателя (HSL для каждого RACCT).
Переменные процентные значения – значения у записей получателя воспринимаются как проценты. То есть 100 или 200 на счетах в данном примере будут восприниматься как проценты. Соответственно 6 000 распределится как 6 000 и 12 000.
Переменные коэффициенты – значения у записей получателя воспринимаются как коэффициенты. То есть 100 или 200 на счетах в данном примере будут восприниматься как множитель. Соответственно 6 000 распределится как 600 000 и 1 200 000.
Переменная, равно – равномерно распределит на каждую запись получателя, 6 записей получат по 1 000 от распределяемых 6 000.
Поле Шкала:
Без масштабирования – ссылочные базы остаются как есть.

Стандартное масштабирование – если сумма ссылочных баз больше или равна нулю, наименьшее отрицательное значение устанавливается равным нулю. Соответственно увеличиваются и другие ссылочные базы. Если сумма ссылочных баз равна нулю, наибольшее положительное значение устанавливается равным нулю. Другие ссылочные базы соответственно уменьшаются.
В нашем примере -200 стало 0, -100 стало 100, а 0 стало 200.
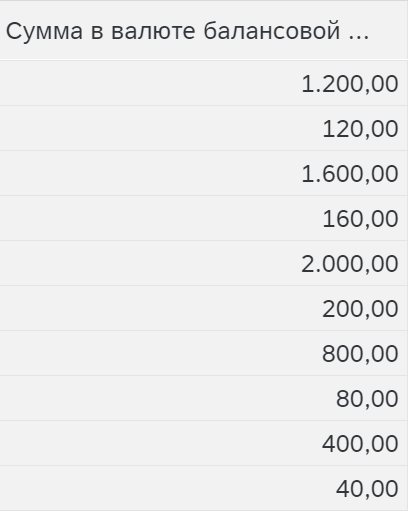
Абсолютное значение (от отрицательного к положительному) – меняет все – на +, то есть -100 и -200 станут 100 и 200 соответственно.
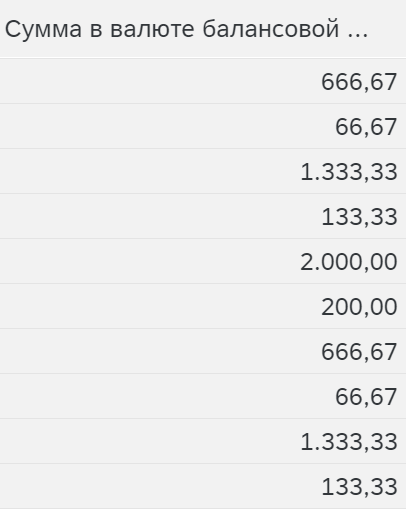
Отрицательная ссылочная база на нуль – отрицательные значения становятся нулем.
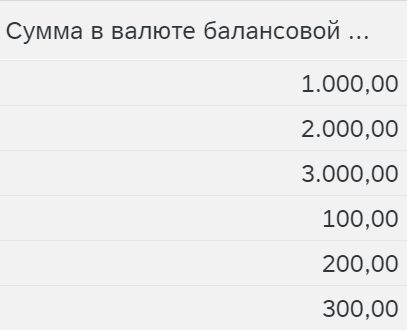
Наименьшая отрицательная ссылочная база на нуль – наименьшая отрицательная ссылочная база равна нулю. Все остальные ссылочные базы соответственно увеличиваются. В нашем примере соответствует варианту Стандартное масштабирование.
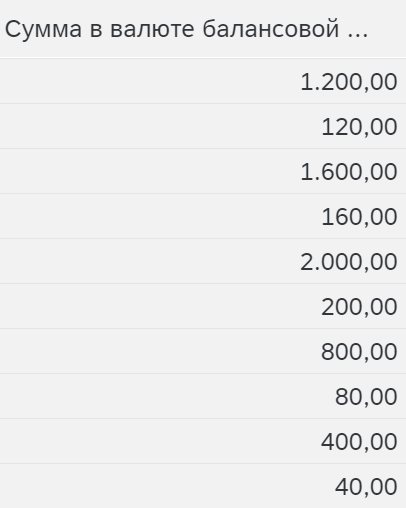
Наименьшая отрицательная ссылочная база на нуль, но нуль = нуль – аналог предыдущего, только нуль остался нулем, то есть в нашем случае -200 стало 0, -100 стало 100, а 0 остался 0.
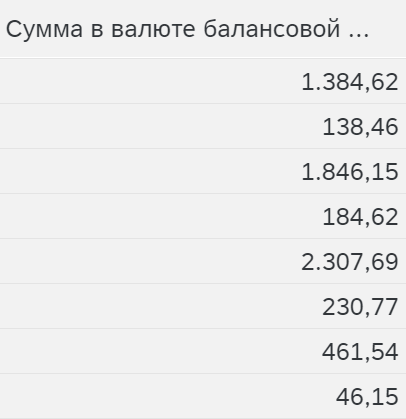
Поле Результат драйвера:
Показывает доли по которым будут распределятся показатели отправителя. Удобно, когда большие и разнообразные значения отправителя, и нужно понять какие пропорции используются.
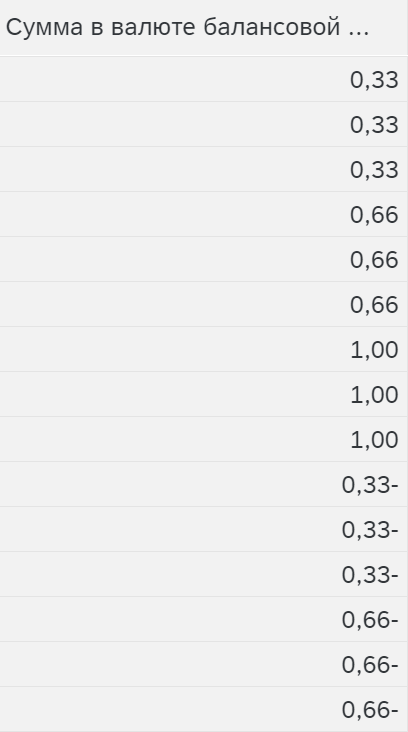
В данном случае по 3 записи на каждое значение ссылочной базы. Так как запись отправителя с нулевым значением пока еще учитывается. Это еще не нулевой результат, который игнорируется и не выводится из-за настроек в заголовке функции распределения, а промежуточный результат. То есть система отображает то на что она умножит значение отправителя.
Тип правила:
Прямое – система перенесет значения от отправителя к получателю.

Косвенное – система распределит значения отправителя с сохранением аналитики получателя и выполнит агрегацию
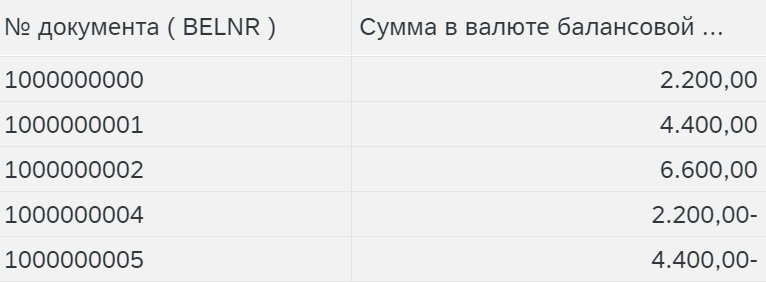
Косвенное детально – для дифференциации затрат и “протягивании” номера документа через распределение нужно выбрать этот тип правила.

Итеративное распределение (циклы распределения)
Теперь допустим что среди получателей материалов, которые были отпущены со склада, присутствует сам склад. То есть в ссылочной базе получателя будет МВЗ склада (в нашем примере CC01_01_01). После распределения затрат МВЗ не закроется в 0. Но все затраты должны уйти на конечных получателей, МВЗ CC02_01_01, CC02_01_02 и т.д. Для выполнения циклов распределения используем опцию Повторная = ‘Да’ в заголовке функции.
Для данного примера изменим записи отправителя и получателя для упрощения. Добавим в ссылочную базу МВЗ-склад CC01_01_01 (записи можно править прямо в Среде моделирования)


В настройках функции на вкладке “Расшир” (видимо Advance) указываем число повторов. Можно достаточно большое, так как все равно цикл остановится при достижении нулевой суммы к распределению.
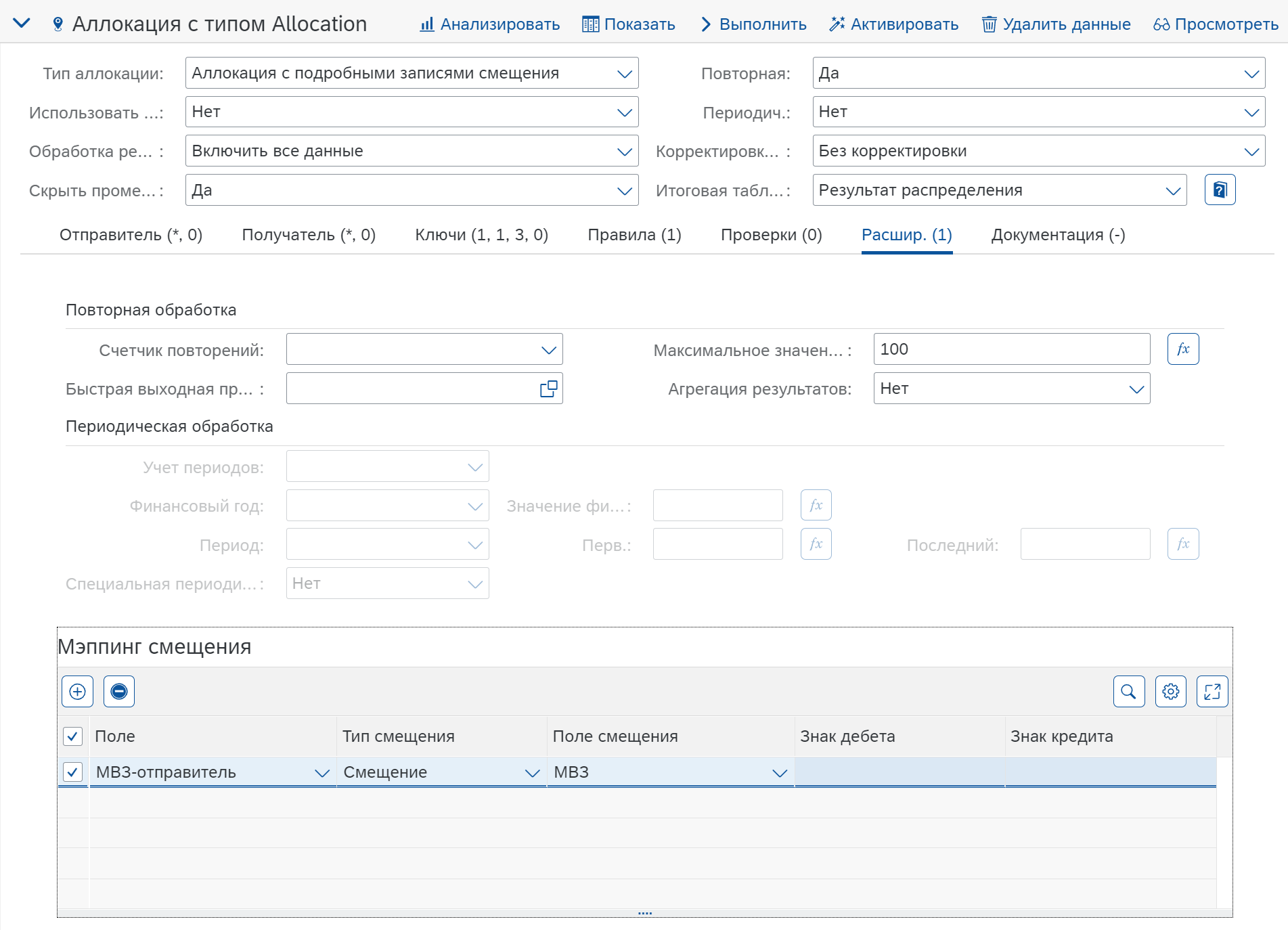
Мэппинг смещения
Важно в разделе “Мэппинг смещения” указать, настройку для последующей итерации цикла. Значение в поле МВЗ-отправитель переносится из поля МВЗ предыдущей итерации цикла. То есть, результат распределения будет входящим значением для следующей итерации. Система передаст значение в поле МВЗ-отправитель, по которому настроен фильтр. Он позволит распределять значения только по МВЗ склада (CC01_01_01).
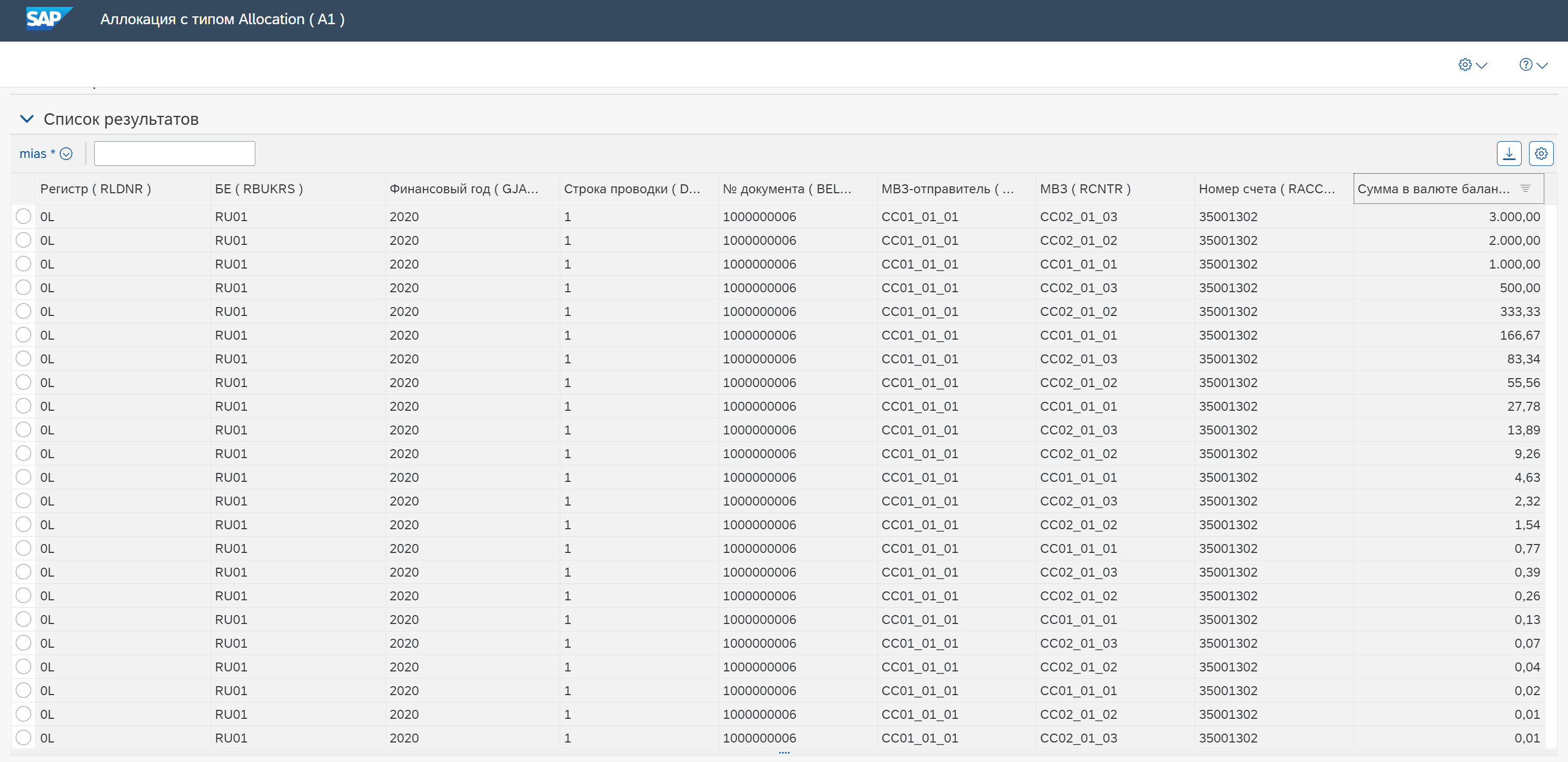
В результате 1000, которую система распределила обратно на склад в первой итерации, система повторно распределит. Остальные МВЗ будут отфильтрованы. 166,67 со второй итерации система опять распределит на получателей, остальные МВЗ будут отфильтрованы. Потом 27,78 и так до нуля.
В результате на МВЗ CC02_01_02 и СС02_01_03 будет 6 000.
Корректировка значения
Еще одна полезная опция “Корректировка значения”. С ее помощью можно отнести разницы от округления. Они возникают при распределении на последнюю строку или строку с максимальным значением. В данном примере это поможет избавиться от разницы 0,02. Она появятся на конечных МВЗ, если не использовать корректировку.